Recognition accuracy for difficult-to- distinguish actions is improved by up to 53% with learning both video and sensor information
March 12, 2020
Hitachi, Ltd. has developed a human action recognition AI technology that can recognize actions in video in which a part of the person is occluded or where there is slight variation in motion that is difficult to distinguish. In this technology, by making AI learn the video and sensor signal obtained from multiple body-worn sensors in advance, it is possible to use only video cameras to capture in real time slight variation in actions without using other sensors. We achieved high accuracy in action recognition in real surveillance videos even when a part of the person’s body was obscured. In comparison with other action recognition technology that normally learns the information only from video, our technology could achieve an improvement of up to 53 percentage points for difficult-to-distinguish actions. It is possible to expand the use of this technology to applications such as detecting suspicious behavior in low visibility and crowds or thickets, as well as in accidents caused by minor collisions between workers and machinery in factories. In the future, Hitachi will apply this technology to video surveillance systems to contribute to a safe and secure society and expand its support for safety operations in factories.
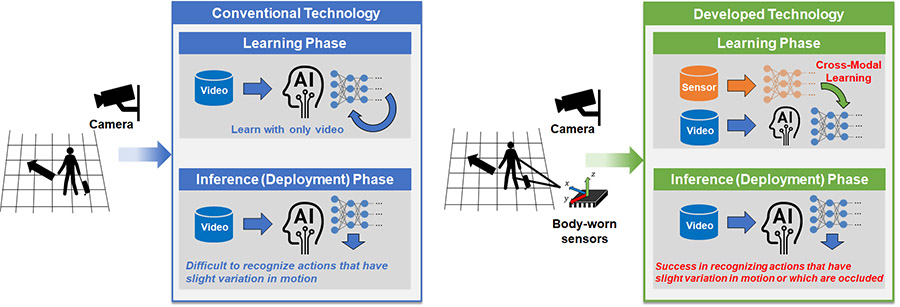
Fig. 1 Difference in comparison with conventional technology

Fig. 2 Sample images of actions from published dataset
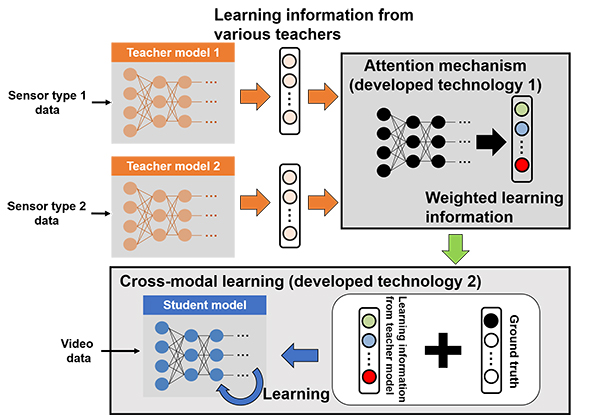
Fig. 3 Details of developed cross-modal recognition technology
Which kind of body part sensor information is useful for recognition varies depending on the action that the user wishes to distinguish. When incorporating sensor information into video-based recognition model, if it is learned with indiscriminately as supervision signals from sensor, there is a possibility that sensor information from some body parts which are not useful for action recognition will be learned. In the case of the new technology, an attention mechanism*1 has been developed that enables dynamic selection of sensor information for body parts which are useful for the action to be recognized, making it possible to effectively use action information from sensors in video model learning.
This technology has made it possible to construct AI by combining different types of information, such as sensors and images. This approach applies a method of making student models learn information from teacher models, which is known as knowledge distillation*2. The teacher model is constructed by associating learning information selected automatically from sensor information and ground truth relating to actions in videos. The student model is constructed as a model that recognizes actions based on videos alone, and the outputs of teacher model is learned by student model along with the ground truth of related actions (cross-modal learning*3). As a result of this, the inference abilities of the sensor information-based teacher model, which is sensitive to subtle motion variation and offers robust performance in cases of occlusion, are transferred to the video-based student model. When this technology is applied to video surveillance systems, it will be possible to capture slight motion variation and recognize human actions with a high degree of accuracy even with a system that performs solely on camera videos, without sensors through the use of a student model that has completed learning.
The present research demonstrates the results when video model learns the side information from sensors, while applications in field others than action recognition may also be possible, such as using the technology for action analysis based on sensors only by conversely using videos as the teacher, or performing robust human detection that is effective even when the angle of view varies by learning the mutual image information from different angles. With the aim of further testing this technology, Hitachi has made the large-scale dataset containing sensor and image information that it has constructed publicly available*4. Going forward, Hitachi intends to hold a series of related events and workshops for the purpose of stimulating research in this field and creating an environment that enables collaborative technological development.
For more information, use the enquiry form below to contact the Research & Development Group, Hitachi, Ltd. Please make sure to include the title of the article.
