Both in business and everyday life, we are seeing an increasing number of scenarios dealing with big data.
To address the requirements, "stream data processing", capable of processing large amount of data in sub-millisecond latency, is getting popular.
Recognizing the potential of the technology ahead of others, Hitachi has started the research more than 10 years ago and successfully productized it.
In this article, we interviewed the researchers involved in this technology and introduce their persistence of the way of data processing since before the term "Big Data" became popular.

IMAKI Tsuneyuki
Senior Researcher

NISHIZAWA Itaru
Project Manager
(Publication: January 27, 2017)
IMAKINowadays you may often hear the word "IoT," or Internet of Things. We are amidst an era when devices are equipped with sensors and communication functions and are connected through the Internet. For example, manufacturing equipment is now furnished with many sensors to detect temperature and moisture. Such detected data is monitored and, when the values are extraordinary, the production line may be stopped or temperature adjusted. When such controlling operations are made, a massive volume of data coming from the sensors must be processed on a real-time basis. When a piece of data comes in, it must be processed within milliseconds or even in microseconds. That's what matters.
Today, we'd like to introduce "stream data processing," which is a technology to process continuously inflowing data, akin to the flow of a river, on a real-time basis without holding the data in a storage device or a database.

IMAKIIn the conventional processing method that utilizes a database, the data entered into storage devices is what is processed, and instructions (queries) are issued by humans. For example, if you monitor the sensors of manufacturing equipment and wish to detect any machine with an average temperature of over 900 degrees Celsius, you input the temperature data of all the machines for an entire day into storage devices. Then you ask the question, "Are there any machines with an average temperature of over 900 degrees Celsius?" The stored data is processed to produce the answer.
With stream data processing, instructions (queries) are set before the data comes in. For example, you define an instruction in advance as that an alert must be provided when the average temperature of certain equipment out of the latest 10 pieces of data exceeds 900 degrees Celsius. It is as if you set a trap against the flow of data. The moment the data is caught in the trap, or specific conditions, an alert is given. It takes less than a millisecond to issue an alert once data comes in. The data can be processed in such an extremely short period of time. This is a major characteristic of stream data processing.
You can compare it to panning gold. You first store water in a dam, and then pan gold dust. That is the processing method using a database. In contrast, you set a net in a river against the stream and, when a dust of gold comes, you can catch it at that moment. That's how stream data processing works.
NISHIZAWAWhen we tried to commercialize this technology in Japan, the initial reaction came from the financial industry. In the case of financial transactions, it is meaningless to analyze the stock price information for whole day and find the timing of stock trade after the exchange has closed. With stream data processing, if you register the conditions of the trade in advance, it is executed at the moment when the conditions are satisfied.
Figure 1: Structure of "data processing using a database" and "stream data processing"
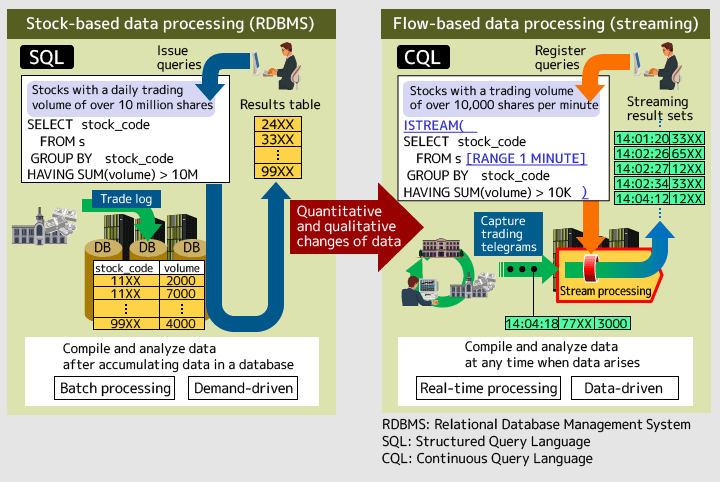
NISHIZAWAThe image of stream data processing is that queries loaded in memory are waiting for data. When a new data item comes in and it is passed through the queries, the necessary part of the data item is processed in memory and unnecessary parts of it are filtered out. This process also has an advantage to keep data freshness.
IMAKITo enable this operation, we narrow the analysis target by segmenting certain parts of the data between "windows," such as the latest 10 minutes or latest 10 cases, so that the target is as close as possible to the present point in time. This method is called a "windowing operation."
Figure 2: How the windowing operation is performed

IMAKIMoreover, difference calculation has been incorporated into stream data processing. This reduces processing burdens and increases processing speed. Suppose a window can hold 10,000 pieces of data, for example, and the sum total must be calculated. When data piece 10,001 comes in, the oldest piece of data goes out. In this case, the sum total is calculated by subtracting the first piece of data, which goes out, and adding piece 10,001, as opposed to calculating from the second piece of data through to piece 10,001. Calculation of the sum total is a fairly simple example, but more complicated calculations, such as join processing, can also be processed in the same manner. That is another characteristic of stream data processing.
IMAKIWe endeavored on how we can lower latency. Latency means the time from the data coming in to the results coming out. In fact, we didn't mind latency too much at first. Rather, we had tried to increase the number of data processed per unit of time, or what is called throughput, and worked to create a prototype for commercialization along this line. The research trend in general had also focused on throughput.

NISHIZAWAStream data processing consists of a number of small processing tasks. The tasks are connected with queues. In our first implementation, if all data items are not finished processing at a certain processing task, the remained data items are temporarily stored in the queue and they wait for the processing. Suppose there are ten data items to process, it is more efficient to process them at once than to process them one by one. However, although it is a very rare case, it could take more than a second before the processing results come out. Our first implementation emphasizing throughput was not accepted by the client in the financial industry. They requested very low latency to place orders when the analysis results indicate that it was time to conduct trades. Of course the requirements vary depending on the customer, in financial transaction scenarios, they wanted latency to be as low as possible rather than have high throughput. This is the reason why we drastically changed our implementation.
IMAKISo we had to manage latency for the client, but it was only about half a month before commercialization of the technology. I remember we worked all night to address the issue. We stuck to a method in which an incoming piece of data is processed from the entry point to the exit point as quickly as possible. The method proved effective, and the data was processed at almost less than a millisecond without varying. As a matter of fact, we were able to obtain a patent for this method, and were honored internally at Hitachi.
NISHIZAWAYes. When I was allowed to conduct joint research with Stanford University in 2002, I chose stream data processing as the research theme. At that time in the U.S., it was a research field that has been drawing attention because the importance of sensor data increased in the future, and it was expected that how to processing method will be the key.
I returned to Japan in 2003, and launched a project on the technology. I came back from the U.S. with the principle of the technology, and then I started to develop our implementation from scratch.
IMAKIDr. Nishizawa invited me to participate in the research. We started the research at a time when the word "Big Data" had not yet become popular in Japan. I recall that, at that time, a variety of data were just about to become available and people talked about "information grand voyage" or "information explosion." When we initiated the project, it was still the early days in terms of global research. Luckily, Hitachi became the first company in Japan to launch stream data processing products.
NISHIZAWAWith a few members, we had developed a prototype system and created some demonstrations that ran on the prototype. For a certain period of time, we continued to appeal the technology by using the prototype and the demonstrations. Finally, we were able to commercialize it in 2008. When the project had started, it was just a small group. But when a new department was established to commercialize the technology, tens of people were assigned at the department. When I moved to the department and gave a greeting to the department in front of the members, it was a really impressive moment for me.

IMAKIA recent trend is that there are a growing number of stream data processing products that run with open source software (OSS). Many of them are packaged with analysis functions such as machine learning. Going forward, we will look to create functions that can clearly differentiate our products from OSS-based products, so that applications prepared for OSS-based products might directly run on Hitachi's products at a faster speed with higher reliability. If that happens, I believe the value of creating stream data processing products would be further enhanced.
NISHIZAWACompared with when we started the research, reactions from customers have changed. Today it is not sufficient to appeal the speed of processing. We will position stream data processing as a solution for "IT × OT," or alignment of information technology and operation technology, which Hitachi pursues. I hope that the stream data processing becomes a strong component that bolsters overall growth.
IMAKIAs I have been engaged in the research of this technology for many years, I have several ideas that have not yet been implemented in products. For the immediate future, I hope to materialize such ideas in order to heighten the presence of products. Well, that would also work to heighten my presence as well (laugh). Specifically, I aim to develop a platform that can perform high-level analyses similar to machine learning. In this regard, I'm currently studying artificial intelligence technologies and the like.
NISHIZAWAI have moved to a new organization that proceeds with customer co-creation of new business. Therefore my goals may be from a slightly different perspective. I believe that Japan must lead and take initiatives in developing basic technologies that can change the conventional scheme of industries. Examples of such basic technologies are the Internet in the telecommunications industry and, arguably, blockchain in the financial industry.

NISHIZAWAThrough the joint research with Stanford University, I experienced a project-type research style. Someone intends to start a certain project and invites people to join. Then, students interested in the subject swarm over it. Brilliant students from a variety of countries gather to the project. A student who is good at programming develops a prototype system, performs experiments on the system and shows the result at a project meeting. Then the next day, another student who is good at theory provides a theorem and proof for the experiments. In this way, practice and theory are combined to make things very quick. The speed of research impressed me a lot.
Moreover, the campus was in a very open environment, and famous researchers from many vendors casually visit and join the project discussions. Indeed, I felt the difference in style compared with the university and corporate laboratories in Japan.
For Japan to compete in the global marketplace, we should be dexterous in creating the basic scheme or structure. I hope to facilitate organization and foster people in Hitachi so that Japan can take initiatives in creating standards. Now I cannot find the exact way how to do it, but I am trying to think about what I should do to achieve that goal.


