29 July 2019

By Chi Zhang
R&D Division, Hitachi America, Ltd.
One of the important objectives in industrial operations is to minimize unexpected equipment failure. Unexpected downtime due to equipment failure can be very expensive for example, an unexpected failure of a mining truck in the field can have a cost of up to $5000 per hour on operations. Besides the cost, unexpected failures can cause safety and environmental hazards and lead to loss of life and property. Traditionally industries have tried to address this problem through time-based maintenance. However, time-based maintenance often causes over maintenance [1], while still not fully being able to address the problem of unplanned downtime. With the advent of IoT, Predictive Maintenance (PdM) is gaining popularity. One of the key applications of PdM implies predicting the future health status of equipment (e.g., failure prediction), and then taking proactive action based on the predictions.
In the Machine Learning (ML) community, Predictive Maintenance (PdM) is typically modeled either as a problem of Failure Prediction (FP) [2] problem or the problem of estimating the Remaining Useful Life (RUL) [3] , whereas in the Prognostics and Health Management (PHM) community, the problem is modeled as that of Health Indicator Learning (HIL). FP answers the question (e.g., yes, no or in a probability) about whether a failure will occur in the next k days and RUL estimates the number of days l remaining before the equipment fails. HIL is the problem of estimating the future "health" of the equipment, as a function of time .
One reason for the popularity of RUL and FP in the ML community is that they are amenable to the traditional machine learning methods - FP is often modeled as a classification problem and RUL is modeled as a regression problem. RUL and FP modeled this way though useful, present operationalization challenges since ML produces black-box models and explainability is extremely desirable in industrial applications. Most domain experts are used to working with degradation curves and expect machine learning methods to produce some- thing similar. Moreover, FP and RUL often do not provide enough information for optimal planning. For example, even if an operations manager is told that the equipment will fail in the next k days, they do not know whether to take the equipment offline tomorrow or on the day, since the prediction provides no visibility into the health of the equipment during the day period (i.e., explanatory power is missing). From a practical standpoint, solving these two problems simultaneously and independently often leads to inconsistent results: FP predicts a failure will happen in days while RUL predicts a residual life of days.
HIL addresses most of these concerns. Since the output of HIL is a health curve , one can estimate the health of the equipment at any time t and observe the degradation over time. Moreover, once the health curve is obtained, both RUL and FP can be solved using the health curve in a mutually consistent manner. However, from a ML perspective, HIL is a hard problem. The problem is essentially that of function learning, with no ground truth - i.e., there is no way to observe the actual health of the equipment during most of the operation. We observe the health only when the equipment fails, and typically most modern industrial equipment are reliable and do not fail very often.
Researchers in the PHM community address the HIL problem by either hand-crafting a Key Performance Indicator (KPI) based on domain knowledge or try to identify some function of sensors that captures the health of the equipment through physical modeling. There are several challenges with these methods. Industrial equipment are complex (e.g., complicated and nested systems), and it is difficult and time-consuming for experts to come up with such KPIs. Addition- ally, domain-specific KPIs are not applicable across industries, so that developing a general method becomes infeasible. Furthermore, equipment is usually operated under varying operating conditions leading to significantly different health conditions and failure modes, making it difficult for a single manually-crafted KPI to capture health.
We propose a machine learning based method to solve HIL problem. Our key insight is that HIL can be modeled as a credit assignment problem which can then be solved using Deep Reinforcement Learning (DRL). The life of equipment can be thought as a series of state transitions from a state that is healthy at the beginning to a state that is completely unhealthy when it fails. RL learns from failures by naturally backpropagating the credit of failures into intermediate states. Therefore, the objective of our method is to discover a health function
such that the following two properties are satisfied:
– Property 1: Once an initial fault occurs, the trend of the health indicators should be monotonic:
– Property 2: Despite of the operating conditions and failure modes, the variance of health indicator values at failures
should be minimized.
To our knowledge, this is the first work formalizing and solving this problem within an RL framework. Additionally, the label sparsity problem (i.e., too few failures) is addressed due to the nature of RL. An example of learned health indicators is shown in Fig. 1.
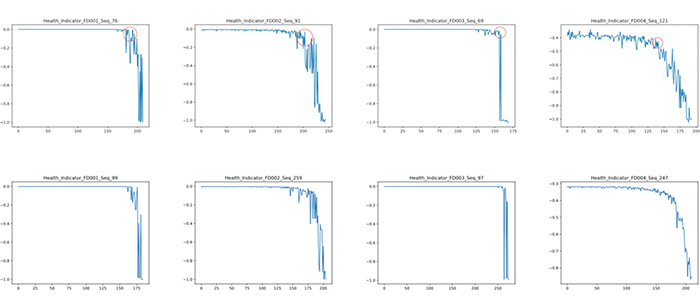
Fig. 1. Health degradation of randomly selected sequences learned by HID. First row: training, second row: testing.
Enlarge (Open new window)
We propose two RL approaches: learning health indicator directly (HID) and health indicator Temporal-Difference learning with function approximation (HITDFA). As HID is a model-based approach, a Markov Decision Process (MDP) model is explicated learned from data, and then the value function that represents health conditions can be solved using iterative policy evaluation. The HITDFA approach takes advantage of deep neural networks to learn value function which does not relay on an explicit MDP model. Memory replay was used to remove the effect of non-i.i.d (independent and identically distributed) property in time series data. Fig. 2 shows the architecture of these two approaches.
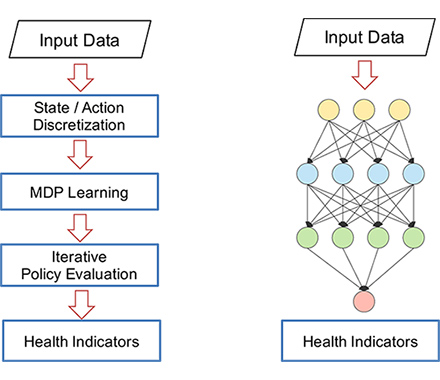
Fig. 2. Architecture of model-based. Left: HID, right:HITDFA.
Additionally, we propose a simple yet effective approach to automatically learn hyper parameters that are best for approximating health degradation behaviors by introducing constraints defined in the two properties described above. Therefore, the proposed method does not require domain-specific KPIs and are generic enough to be applied to equipment across industries.
Finally, we propose the use of the learned health indicators as compact representations (i.e., features) to predict when the equipment is going to reach its end-of-life, which is one of the most challenging problem in PdM. Fig. 3 shows applying a Seq-to-Seq deep neural network [4] to predict remaining useful life using the learned health indicators as the only feature. The predicted health degradation curve provides rich information that can be easily interpreted by operators. For example, the critical points (in orange circle) can be used to decide when to perform preventive maintenance on the equipment to avoid downtime and maximize utilization. As a result, it demonstrates how an explainable health curve is way more useful for a decision maker than a single-number prediction by a black-box model. Therefore, our proposed method not only provides the explanation of health conditions for observed data, but can also predicts the future health status of equipment.
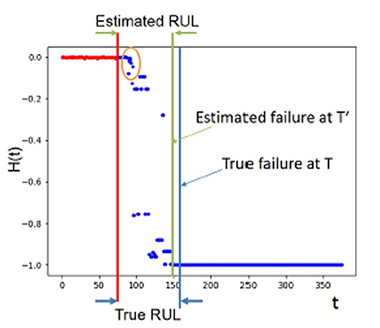
Fig. 3. Learned health indicators are red dots derived from observed sensor measurements, and the blue dots are the predicted health indicators. Green and blue lines represent and the estimated and true failures, respectively.
We believe the proposed approach has a great potential in a broader range of systems (e.g., economical and biological) as a general framework for the automatic learning of the underlying performance of complex systems where labels are unavailable and hand-crafted KPIs are not reliable.
For more details, we encourage you to read our paper, Equipment Health Indicator Learning using Deep Reinforcement Learning at European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD) 2018.
