17 September 2019

By Phong Nguyen
Research & Development Group, Hitachi, Ltd.
Automation in water purification plants (WPPs) can help reduce the problem of expert shortage in the future, as well as optimize operating costs. WPPs usually have two main purposes: to supply sufficient water and to maintain good water quality. Many WPPs in Japan disinfect river water for human consumption as well as industrial use. Further, WPPs need to adapt to the change in water demand (e.g. hot seasons such as summer vs. cold seasons such as winter, morning and night vs. afternoon, etc.) and the turbidity level in raw water that usually comes from a river. Automation in WPPs using artificial intelligence (AI) is a promising solution, not only to address the challenge of declining number of specialists but also to reduce rising costs in water treatment operations. Among all machine-learning algorithms, reinforcement learning has the potential to train the system (an AI agent) to operate a WPP like an expert or better. The agent can learn how to make different types of decisions, such as how much water to take to meet future demands, or how much chemicals to be injected into the raw water for treatment. In our simulated experiments, our agent can outperform experts in making decisions on the intake of water with greater electrical efficiency and achieve a faster and more stable learning process.
To construct an automated system, it is necessary to imitate what an expert would do in a given situation. However, experts in water purification not only follow the general manual, but also take decisions based on years of experience. These rules of actions are vague and not specific enough to be documented into an all-purpose rule-based system. Deep reinforcement learning (DRL) could become a useful solution for automating decision-makings by learning from real-world situations and simulated environments. [1] By defining the goal of taking action and quantifying the rewards as the feedback signal for each decision, a DRL agent can learn to maximize future benefits and even surpass human-level performance. One of the most inspiring examples of the potential of the DRL algorithm is when a computer can defeat the best professional “Go” player in 2017. [2] Before this milestone, many scientists believed that it would take another 100 years for a computer algorithm to perform better than human intelligence in a strategy game. [3]
One of the DRL algorithm variations is the deep deterministic policy gradient (DDPG) that can handle the continuous action space of the learning agent, since the traditional DRL algorithm can only deal with discrete action spaces such as the Go piece position on the Go board. DDPG is an off-policy and model-free algorithm that optimizes policy end-to-end by computing gradient estimates of expected rewards and then updates policy in gradient direction. DDPG also utilizes two neural networks; one is an actor network that generates an action's value, e.g. the quantity of water intake; and the other is a critical network that assesses the goodness of a specific action.
I have two children, and the second child always imitates the older one’s behavior before he can learn by himself. Inspired by this observation of how young children learn from each other in a group, before the DDPG agent began exploring and learning from the simulated environment, I tried to have the DDPG agent imitate the actions of experts. The information collected over several years on how water plants are managed and operated by experts provided comprehensive operational records which proved useful to the DDPG agent. The algorithm begins with DDPG agent at the start of the training stage and follows precisely what specialists have done in the past. It began learning from these experiences rather than exploring the environment from scratch. The DDPG agent would begin exploring new actions after this imitation stage and learn from the typical trial-error method of reinforcement learning algorithm. It turns out that our DDPG agent was able to learn much more quickly than standard algorithms.
System Architecture
A main choice for ensuring appropriate supply will be the quantity of water intake from a river. During the mixing process, the rate of chemical injection will affect the final quality of the water supplied. The reason that the DDPG method is suitable for WPPs operations is WPPs usually have a lot of sensor data and the action space should be in a continuous space (in this case, the amount of intake water and the amount of chemical injection).
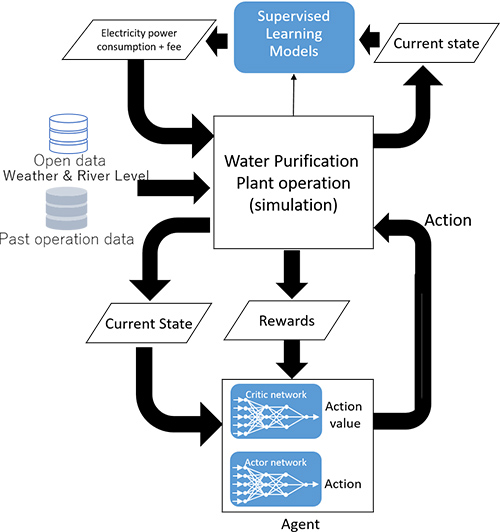
Fig. 1
The controllable actions in a WPP are raw water intake rate (from a river) and chemicals injection rate for purification. I introduce the first task, as the second task is similar. I trained the water intake agent in a simulated environment that tries to recreate the real WPP scenarios. Fig. 1 illustrates our system architecture used for training the water intake agent.
Results
Fig. 2 shows the two methods' efficiency. The DDPG algorithm could converge more quickly with the imitation stage at the start and have more stable training.
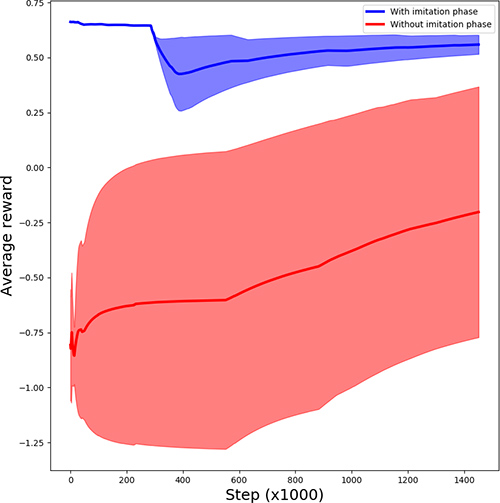
Fig. 2
In the testing phase, we compared the accumulated reward in the training phase between experts and our DDPG agent. We only used the actor network’s action output without any additional noise of action. Fig. 3 displays the result of the accumulated reward of the DDPG agent and the experts during the testing phase. In the final accumulated benefits, the DPPG agent was able to surpass the specialist.
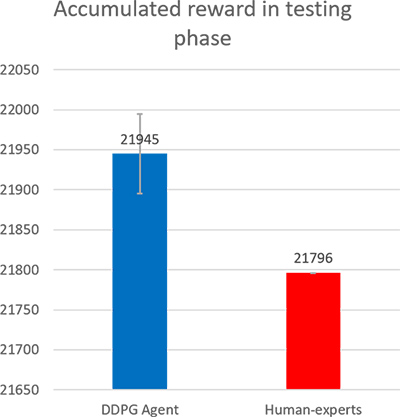
Fig. 3
Fig.4 compares the DDPG agent’s actions and expert’s ones. In addition, Fig.5 compares the water level in the supplied water reservoir managed by the two.
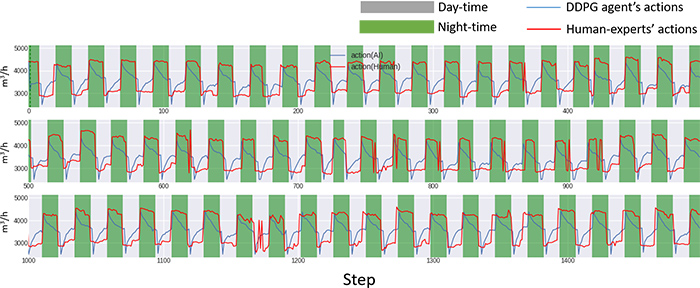
Fig. 4
Enlarge (Open new window)
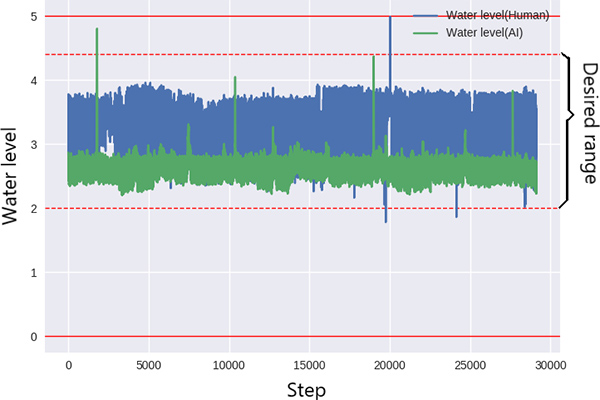
Fig. 5
The full paper and presentation can be found on the conference website, here:
https://www.researchgate.net/publication/
330533198_Automating_Water_Purification_Plant_Operations_Using_Deep_Deterministic_Policy_Gradient
References
