12 December 2019

Yusuke Fujita
Research & Development Group, Hitachi, Ltd.

Shota Horiguchi
Research & Development Group, Hitachi, Ltd.
We recently had the opportunity to present our work on multi-talker speech recognition at INTERSPEECH 2019 conference [1]-[4]. In this blog article, we’d like to share an outline of our presentation which looked at the some of real-world issues in speech recognition and understanding, and how we are tackling them.
Automatic speech recognition (ASR) is a technique to convert human voice into text. Thanks to recent advances in ASR technology, voice-assisted applications such as voice commands to smart speakers, interactive voice response over the telephone, and automated subtitles on TV programs have become familiar. However, most of existing ASR-based systems do not maintain excellent performance in multi-talker situations. One reason is that ASR systems are usually trained with speech data in which only one person is speaking. Therefore, most of ASR systems fail to input overlapping speech by multiple speakers.
To alleviate this overlapping speech problem, we consider two approaches: Speech Separation and Target-speaker ASR. First, we introduce our multi-talker ASR based on speech separation using multi-channel audio. Secondly, we discuss our target-speaker ASR that directly transcribes the target-speaker's text from overlapping speech. Then, we introduce a new technique to detect Who Spoke When; our end-to-end speaker diarization method plays an essential role in multi-talker ASR. Finally, we step forward to a multi-talker ASR application in spoken dialogue systems. In multi-talker situations, speech can be directed not only to a dialogue system but also to another person. We describe our achievement to solve this issue: When Robot Responds to You.
Speech separation is one of common approaches to solve the overlapping speech problem. Speech separation aims at converting a multi-talker mixture speech into the set of single-talker speech. Since two speakers are usually at different positions against microphones, speech separation is realized by using a beamforming technique that enhances a signal from the specific direction using multi-channel audio information. Then, separated speech is fed into ASR.
Hitachi and Johns Hopkins University have organized a team to tackle the challenging task of multi-talker speech recognition (the "CHiME-5 challenge") held in 2018. We developed a combined system of speech separation and ASR. We got 48.2% of word error rate (WER), which was the second-best result in the challenge. The first place was 46.1% given by University of Science and Technology of China [USTC 2018][5].
After the challenge, Hitachi and Paderborn University conducted the further enhancement of the system [Hitachi/UPB 2019-1][1].
Our speech separation and ASR system are depicted in Figs. 1 and 2. First, the Guided Source Separation (GSS) extracts an enhanced speech from multi-channel signals. GSS fully utilizes oracle timestamps of utterances in its mask initialization and update steps of complex Angular Central Gaussian Mixture Model. The enhanced speech is then fed into the ASR system, along with multi-channel signals and speaker embedding (i-vector) of the target speaker. In this paper, we employed six models with different network structures and combined the six outputs by applying N-best ROVER method.
We further reduced the WER by two-stage speech separation approach, which retries speech separation with an estimated target speaker’s speech activity given by the first-stage ASR. To the best of our knowledge, the WER of 41.6% was the best score ever reported until September 2019.
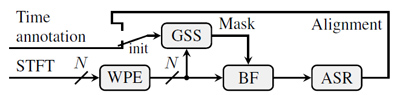
Figure 1: Overview of our frontend, Guided Source Separation (GSS)
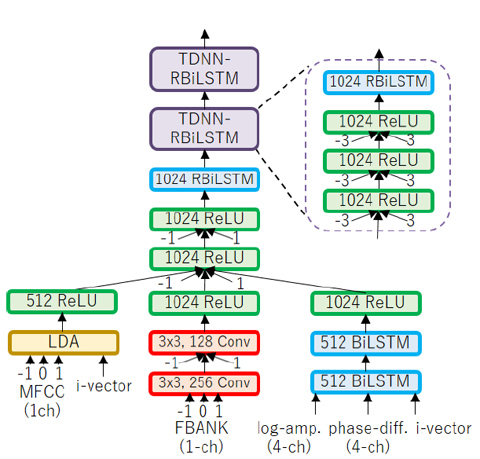
Figure 2: Overview of our backend, CNN-TDNN-RBiLSTM acoustic model
Although the speech separation technology keeps advancing, it is a bit expensive due to the use of a microphone array in which multiple microphones are connected to a single analog-to-digital converter. On the other hand, a human can extract the spoken contents of the target speaker even from monaural audio. The issue of the target-speaker speech extraction without using speech separation and its solution was proposed by NTT in 2018 [NTT 2018][6]. When a mixture speech and another target-speaker speech (referred to as an "anchor speech") are fed into the target-speaker ASR (TS-ASR) system, it outputs the target speaker’s text in the mixture speech. Although the anchor speech is an additional requirement, it is reasonable to use such an anchor in a meeting scene where each speaker utters multiple times.
Hitachi and Johns Hopkins University proposed an advanced method of TS-ASR in September 2019 [Hitachi/JHU 2019-2][2]. More accurate target-speaker ASR is achieved by appending novel output layers for non-target speaker’s text, as shown in Fig. 3. The experiment on the simulated mixture dataset showed that the conventional TS-ASR achieved 18.06% of WER while a standard ASR produces 80%. Finally, the proposed TS-ASR achieved 16.87% of WER.
We also evaluated the WERs for non-target speakers. Surprisingly, WERs of non-target speakers (18.38%) are comparable to those of target speakers (16.87%), although only target anchor speech is fed into the ASR.
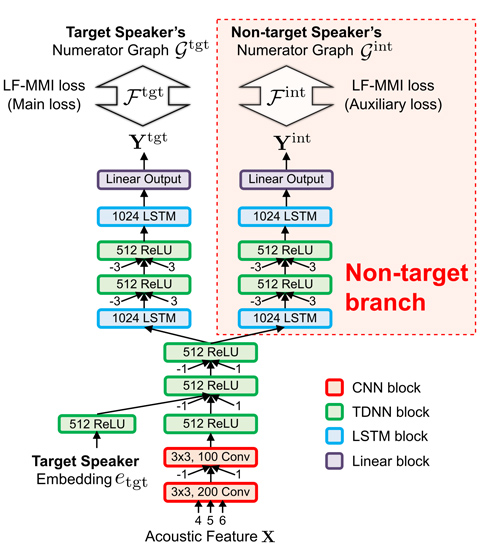
Figure 3: TS-ASR with output layers for non-target speakers
When we transcribe a multi-talker conversation, we need a speaker label for each speech segment as well as an ASR result. Also, an anchor speech, another speech segment of the target speaker, is desired for accurate multi-talker ASR as described in the previous section. To obtain such speech segments, speaker diarization technique is required. Speaker diarization module detects "who spoke when."
Although speaker diarization has been studied for many years using telephone and meeting conversations, multi-talker overlapping speech has been excluded from their evaluations. It seemed hard to deal with multi-talker overlapping speech.
Hitachi and Johns Hopkins University proposed a simple yet effective method for speaker diarization that handles overlapping speech in September 2019 [Hitachi/JHU 2019-3][3]. Unlike the typical speaker diarization methods that need a complicated pipeline of several individually optimized models, our method needs only one model trained with large-scale multi-talker overlapping speech, as shown in Fig 4. Our end-to-end diarization model architecture, named EEND, is shown in Fig. 5, which takes audio features as inputs and outputs speech mask for each speaker. When training, permutation between neural network output and ground truth labels arises, and we resolved this problem by utilizing permutation invariant training.
Our evaluations on highly overlapped speech showed that our model outperformed the typical speaker diarization method. Furthermore, we found that the model architecture based on self-attention mechanism, which considers a pairwise similarity between two frames, impressively reduce the diarization errors. Finally, we reported 10.99% of diarization error rate while state-of-the-art conventional method produces 11.52% on the widely used telephone speech dataset (See also https://arxiv.org/abs/1909.06247 accepted at upcoming IEEE ASRU 2019 workshop).
The codes to reproduce our experimental results are publicly available at the below.
https://github.com/hitachi-speech/EEND
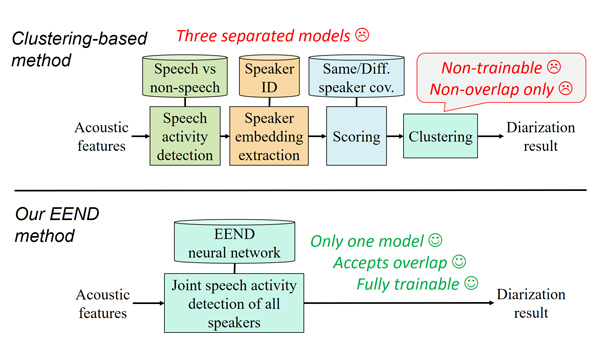
Figure 4: System diagrams for speaker diarization
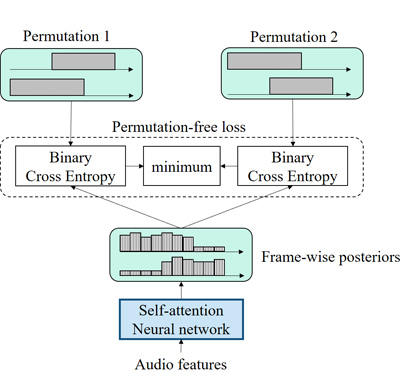
Figure 5: End-to-end diarization model for two-speaker cases
Even if multi-talker ASR worked perfectly, it is still not enough for a spoken dialogue robot operated in public spaces. A robot cannot determine only by ASR results whether a detected utterance was directed to the robot; an utterance is sometimes directed to the robot, and at the other time to another person, even if the content of the utterance is completely the same. This may cause the interruption of the robot to human-human conversation. To avoid this, the robot must classify whether the detected utterance is directed to the robot or not. This task is called response obligation detection.
Hitachi proposed a response obligation detection method using multimodal information, for instance, text, audio, and visual information [Hitachi 2019-4][4]. The architecture of our response obligation detector is shown in Fig. 6.
We evaluated our method on real-world datasets by operating a robot in a station and a commercial building. Evaluation on the datasets showed that our detector achieved higher accuracy than unimodal baselines on in-domain evaluations.
Furthermore, assuming that the detector is used in various environments, we also proposed an unsupervised online domain adaptation method. We observed that domain-adaptation performed very well both from the station to the building, and from the building to the station.
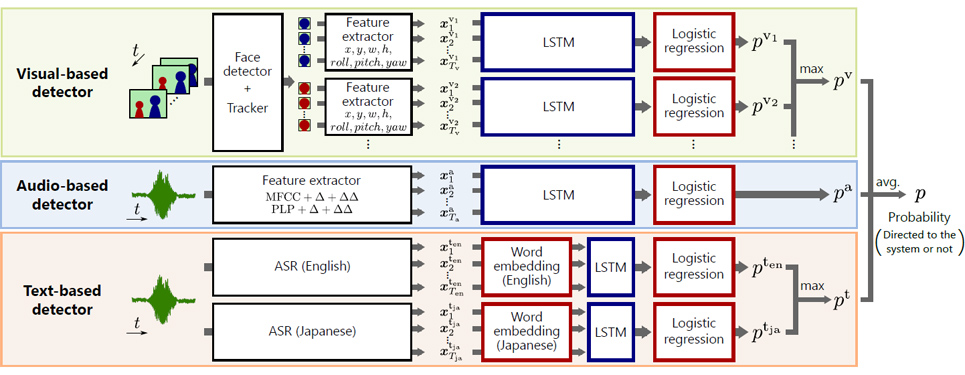
Figure 6: Multimodal response obligation detector
In this post, we presented our recent advances in multi-talker speech recognition. Multi-talker overlapping speech is a frontier problem on real-world ASR applications. Throughout this post, we showed how Hitachi R&D and our collaborators have tackled the problem.
Finally, our R&D efforts are not limited to the ASR topic. We also have a bunch of achievements in computer vision, acoustics, natural language processing, and data science. For further information, please see our publication list: https://hitachi-speech.github.io.
