17 February 2020

Walid Shalaby
R&D Division, Hitachi America, Ltd.
Knowledge Base (KB) construction from text aims at converting the unstructured noisy textual data into a structured task-specific actionable knowledge that captures entities (elements of interest (EOI)), their attributes, and their relationships. KBs are key ingredient for many AI and knowledge-driven tasks such as question answering, decision support systems, recommender systems, and others. KB construction has been an attractive research topic for decades resulting in many general KBs such as DBPedia, Freebase, Google Knowledge Vault, ConceptNet, NELL, YAGO, and domain-specific KBs such as Amazon Product Graph, Microsoft Academic Graph.
The first step toward building such KBs is to extract information about target entities, attributes, and relationships between them. Several information extraction frameworks have been proposed in literature including OpenIE, DeepDive, Fonduer, Microsoft QnA Maker, and others. Most of current information extraction systems utilize Natural Language Processing (NLP) techniques such as Part of Speech Tags (POS), shallow parsing, and dependency parse trees to extract linguistic features for recognizing entities.
In this research, we focus on building a framework for constructing a KB of equipment components and their problems entities with “component <has-a> problem” relationship. There is a tremendous volume of unstructured textual content that contains such information in unstructured free text format or semi-structured tables format. Creating a structured representation of such entities has many benefits. For example, one of Hitachi’s outstanding technologies in this space is an AI-powered solution for monitoring, controlling, and optimizing fleet maintenance operations. At its core, this solution utilizes modern user interfaces like voice to interact with its users to give the right recommendation to the driver and the technician based on verbal complaints and vehicle sensor data. A KB of vehicle-related components and their associated problems would enable better understanding of what the user is complaining about.
In addition, this research enables rapid deployment of Natural Language Understanding (NLU) interfaces with good starting point accuracy. The KB is among a set of tools that could potentially automate the whole deployment process making it easy for Business Unites (BUs) to use NLU systems of any voice UI vendor.
Unlike previous work [1], our framework not only extract components and part names, but also their associated problems. We start with syntactic rules rather than seed head nouns as in [1]. The rules require less domain knowledge and should yield higher coverage. We then reorganize the extracted vocabulary of components and problems into a hierarchy to create a knowledge graph of such extracted entities. Unsupervised curation and purification of extracted entities is another key differentiator of our framework compared to prior work. The proposed framework utilizes a state-of-the-art deep learning for sequence tagging to annotate raw sentences with component(s) and problem(s).
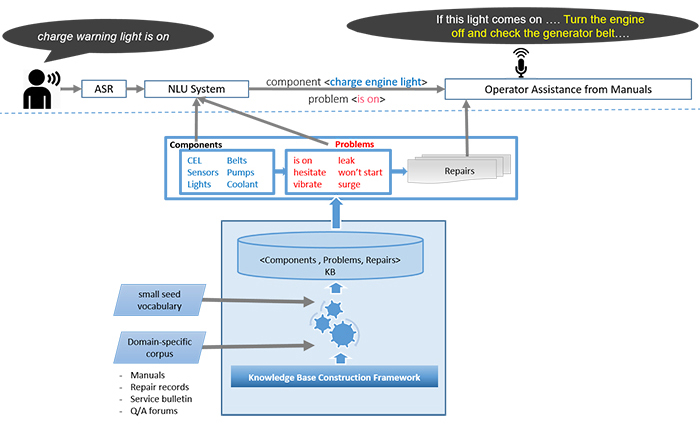
Fig.1. High-level architecture of our chatbot for responding to vehicle-related complaints
As shown in Figure 1, we create a vocabulary of components, problems, and possibly repairs through a knowledge construction pipeline by reading domain-specific text corpora such as service bulletins, manuals, maintenance and repair records, and public Questions and Answers (QA) forums. Once created, this vocabulary can be used by any NLU and operator assistance system to better understand and serve user complaints.
Our KB construction framework works through two main stages: 1) domain-specific syntactic rules leveraging POS to create an initial vocabulary of target entities, and 2) a neural attention-based Sequence2Sequence (seq2seq) model called S2STagger which tags raw sentences end-to-end identifying components and their associated problems, and also enabling the extraction of more entities from structures not covered by the syntactic rules.
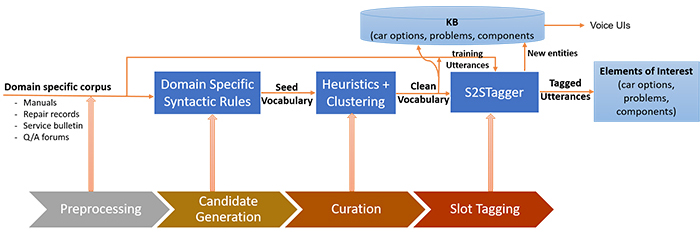
Fig.2. Knowledge base construction framework is a pipeline of five main stages
Figure 2 shows the architecture of our KB construction framework. The proposed framework is organized as a pipeline. We start with a domain-specific corpus that contains our target entities. We then process the corpus through five main stages including preprocessing, candidate generation using POS-based syntactic rules, embedding-based filtration and curation, and finally enrichment through training a seq2seq slot tagging model. Our pipeline produces two outputs:
Table 1 shows sample complaint utterances from QA posts. As we can notice, most of these utterances are short sentences composed of a component along with an ongoing problem.
After text preprocessing, we extract candidate entities using a set of syntactic rules based on POS tags of complaint utterances.
Table 1. Sample vehicle complaint utterances (problems in red, components in blue)
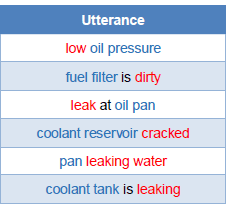
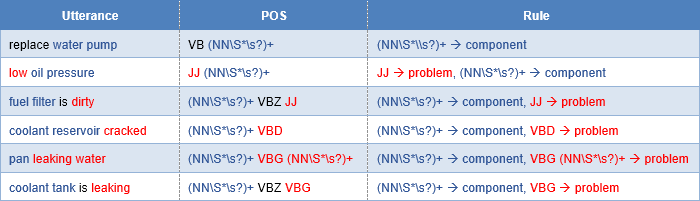
Table 2 shows the rules defined for the most frequent six POS patterns. In the curation stage, we prune incorrect and noisy candidate entities using weak supervision. We employ different weak supervision methods to prune incorrectly extracted entities including statistical-based pruning, linguistic-based pruning, embedding-based pruning, and sentiment-based pruning.
Table 2. POS-based syntactic rules for candidate entity generation (problems in red, and components in blue)
In this research, we propose a neural attention-based seq2seq model called S2STagger to tag raw sentences and extract target entities from them. This model serves as a more practical and efficient AI-based solution that goes beyond the predefined syntactic rules. To train S2STagger, we create a dataset from utterances that match our syntactic rules and label terms in these utterances using the inside-outside-beginning (IOB) notation. For example, “the car air pressure is low” would be tagged as “<O> <car-options> <B-component> <I- component> <O> <B-problem>”. As the extractions from the syntactic rules followed by curation are highly accurate, we expect to have highly accurate training data for our tagging model. As shown in Figure 3, S2STagger utilizes an encoder-decoder Recurrent Neural Network architecture (RNN) with Long-Short Term Memory (LSTM) cells [3]. During encoding, raw terms in each sentence are processed sequentially through an RNN and encoded as a fixed-length vector that captures all the semantic and syntactic structures in the sentence. Then, a decoder RNN takes this vector and produces a sequence of IOB tags, one for each term in the input sentence. Because each tag might depend on one or more terms in the input but not the others, we utilize an attention mechanism so that the network learns what terms in the input are more relevant for each tag in the output [4, 5].

Fig.3. S2STagger utilizes LSTM encoder/decoder to generate the IOB tags of input utterance. Attention layer is used to learn to softly align the input/output sequences.
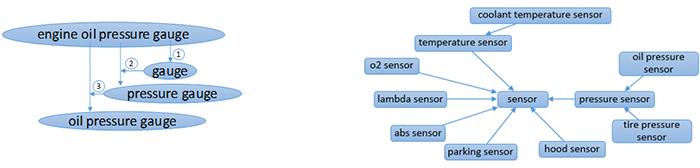
Fig.4. Component hierarchy construction through backward traversal.
Left – traversal through “engine oil pressure gauge” resulting in three higher level components. Right – example hierarchy with “sensor” as the root supertype component.
After training S2STagger, we use it to tag the remaining utterances in our dataset which do not match our syntactic rules. Then, we consolidate the entities from the curation stage along with the entities discovered by S2STagger to create our KB of components and problems entities as shown in Figure 2. Importantly, our trained S2STagger model can be used to tag newly unseen utterances allowing the proposed KB framework to scale efficiently whenever new utterances are collected.
A second source of enrichment is through component backward traversal; here we propose using a simple traversal method to create a hierarchy of supertype components from the extracted components vocabulary after curation and tagging using S2STagger. As shown in Figure 4, we consider each extracted component (subtype) and backward traverse through its tokens one token at a time. At each step, we append the new token to the component identified in the previous traversal step (supertype). For example, traversing “engine oil pressure gauge” will result in “gauge,” “pressure gauge,” and “oil pressure gauge” in order. As we can notice, components at the top of the hierarchy represent high level and generic ones (supertypes) which can be common across domains (e.g., sensor, switch, pump, etc.). The hierarchy allows introducing “subtype <is-a> supertype” relationship between components enriching the KB with more supertype components. A third source of enrichment is through problem aggregation; the new components identified through backward traversal will initially have no problems associated with them. We propose using a simple aggregation method to automatically associate between supertype components and problems of their subtypes. First, we start with the leaf subtype components in the hierarchy. Second, we navigate through the hierarchy upward one level at a time. At each step, we combine all the problems from the previous level and associate them to the supertype component at the current level. For example, all problems associated with “oil pressure sensor,” “tire pressure sensor,” etc. will be aggregated and associated with “pressure sensor.” Then problems of “pressure sensor,” “o2 sensor,” “abs sensor,” etc. will be aggregated and associated with “sensor”. This simple aggregation method allows introducing new “supertype <has-a> problem” relationships in the constructed KB.
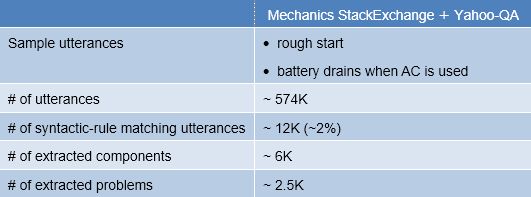
We experimented our framework with two datasets related to automotive troubleshooting. First, a dataset of QA from the public Mechanics StackExchange QA forum [6]. Second, another subset questions related to maintenance from the Yahoo QA dataset. Table 3 shows some example utterances and statistics from the datasets. As we can see, the coverage of syntactic rules is noticeably low. This demonstrates the need for a learning-based entity extractor such as our proposed S2STagger model to harness the knowledge from utterances not matching the predefined rules.
Table 3. Dataset statistics
We evaluated S2STagger qualitatively on a test set of utterances to understand the strengths and weaknesses of the model. For comparison, we built two other models using off-the-shelf NLU technologies. First, a skill (AlexaSkill) using Amazon Alexa Skills kit. Second, an agent (DiagFlow) using Google Dialog Flow. With both models, we defined utterance structures equivalent to the syntactic rules structures. We also fed the same curated entities in our KB to both models as slot values and entities for AlexaSkill and DiagFlow respectively. For fair comparison, we trained our S2STagger on all the tagged utterances. Initial results show superior performance of the proposed S2STagger slot tagging model over the two other baseline models. S2STagger also provides scalable and efficient mechanism to extend our KB beyond the handcrafted extraction rules.
For more details, we encourage you to read our paper, “Building chatbots from large scale domain-specific knowledge bases: challenges and opportunities,” which is available on Arxiv [7].
