16 March 2020

By Ioannis Souflas, Ph.D.
European R&D Centre, Hitachi Europe Ltd.
Accepting autonomous vehicles as a reliable and safe transportation service requires the realization of smooth and natural vehicle control. The plethora of driving data captured from modern cars is a key enabler for solving this problem. Our work on data-driven perception and planning systems for autonomous vehicles was recently presented at the AutoSens conference in Brussels.[1] In this article, we summarize the key points of this presentation with the purpose of highlighting the benefits and limitations of data-driven solutions for autonomous vehicles.
Autonomous vehicle software is a topic that has drawn a lot of attention over the last decade. Although several different software architecture approaches can be found in literature, there are two major paradigms[2] dominating the research and development community (Fig. 1):
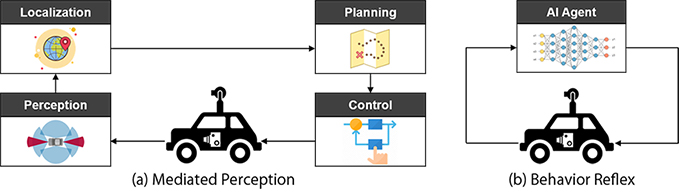
Figure 1: Autonomous driving software paradigms
Considering the benefits and limitations of each approach and based on our experimentation and recent findings from other researchers in the field[4,5], we have concluded that combining the two paradigms would allow us to have better reconfigurability, transparency, debuggability and maintainability which are all necessary in order to produce high quality and safe software for autonomous driving. In further details and relating to how humans drive, we know that Perception and Planning are two key sub-modules responsible for “Environmental Cognition” and “Decision Making”. Hence, we have combined the Mediated Perception and Behavior Reflex paradigms by enriching the Perception and Planning sub-modules with state-of-the-art AI and data science techniques (Fig. 2).
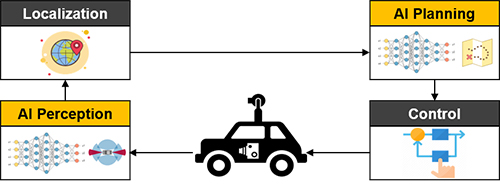
Figure 2: Proposed autonomous driving software paradigm combining the benefits of Mediated Perception and Behavior Reflex approaches
Our work on data-driven autonomous driving software was part of the HumanDrive project undertaken in the UK where we led the prototyping of pioneering AI technology to develop natural human-like vehicle control using machine learning.[6] As part of this activity we have developed a full software stack that enabled us to deploy data-driven perception and planning solutions. At the top level (Fig. 3), the software is comprised of the following sub-modules:
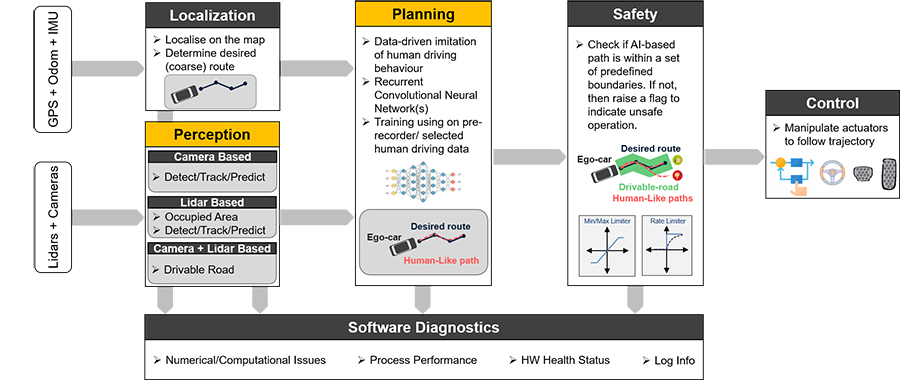
Figure 3: Top-level system architecture - block diagram
Emphasizing in the perception system, we have split the software into three distinct layers, the Machine/Deep Learning layer, the Engineering layer and lastly the Output layer (Fig. 4). The Machine Deep Learning layer consists of multiple deep neural networks that use raw sensor data from cameras, LiDARs or both and output information about the surrounding objects, occupied area and drivable road. The Engineering Layer is responsible to fuse the information provided from the different deep neural networks, filter/track their movement based on prior knowledge about the kinematics/physics of the objects, and finally provide a short-term prediction about the future state of the objects based on their history. At last the Output Layer converts the processed information into the appropriate data representations e.g. grid format, vector format etc., in order to be used by the planning module.
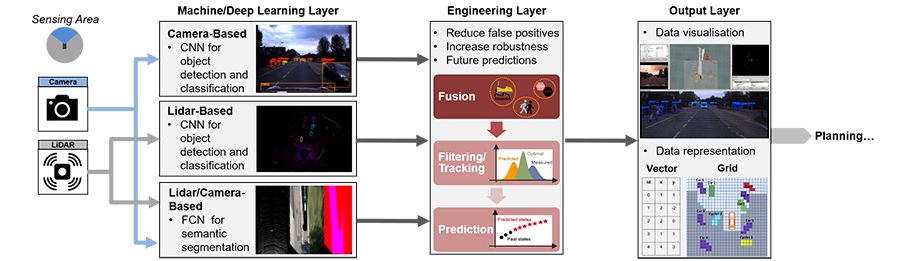
Figure 4: Data-driven perception system architecture
Moving to the planning system (Fig. 5), the core of the solution is a multiple input/output Recurrent Convolutional Neural Network (RCNN) that is responsible to imitate and predict the human driving behavior in terms of future yaw rate and speed demands. The planning network, namely PlanNet, uses current and historical information about the environment perception in the form of occupancy grid sequence and information about the desired route ahead of the ego-vehicle to predict the best set of yaw rate and speed demands. Following, this step a Trajectory Generator is responsible to convert the predicted sequence of yaw rates and speeds into a trajectory based on a physics-based vehicle model.[7]
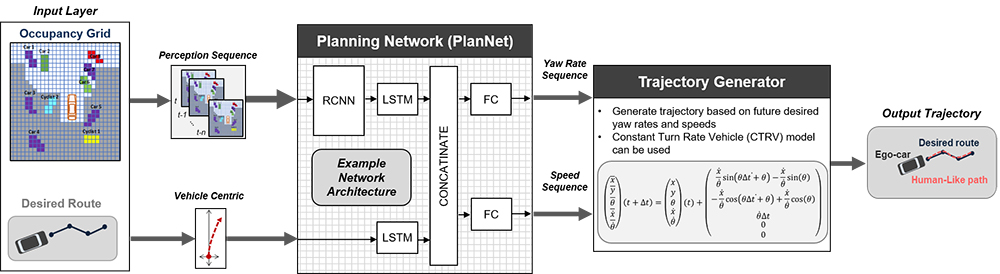
Figure 5: Data-driven planning system architecture
As it can be understood from the above explanation of the data-driven perception and planning sub-modules, the backend of these systems consists of deep neural networks that need to be “fueled” by data. For this purpose, we have developed a complete pre-processing pipeline of analysis, synthesis and labelling[8] tools that allow us to create unbiased, balanced datasets with high information content prior to any machine learning training and validation activities.
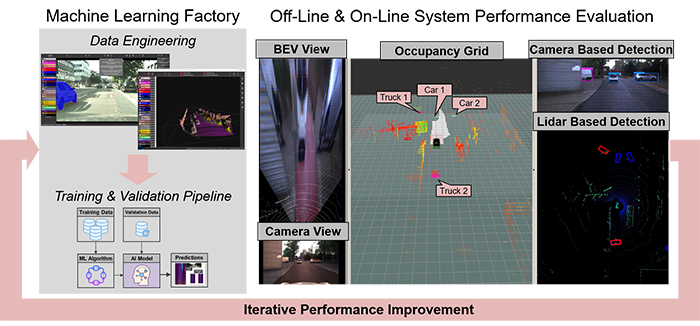
Figure 6: Pipeline for accessing and improving machine learning models
Finally, a software architecture that has at its core state-of-the-art deep learning and data science tools requires efficient software development, dependencies management and testing practices. With respect to software development and dependencies management we have used container technologies which is essential for seamless integration, compatibility and maintainability of the software. Regarding the testing practices, we have followed a working pipeline which starts with early functionality prototyping and testing using Software-in-the-Loop (SiL) to reassure bug free deployment and then move to real-world testing for refinement, calibration and system verification (Fig. 7).
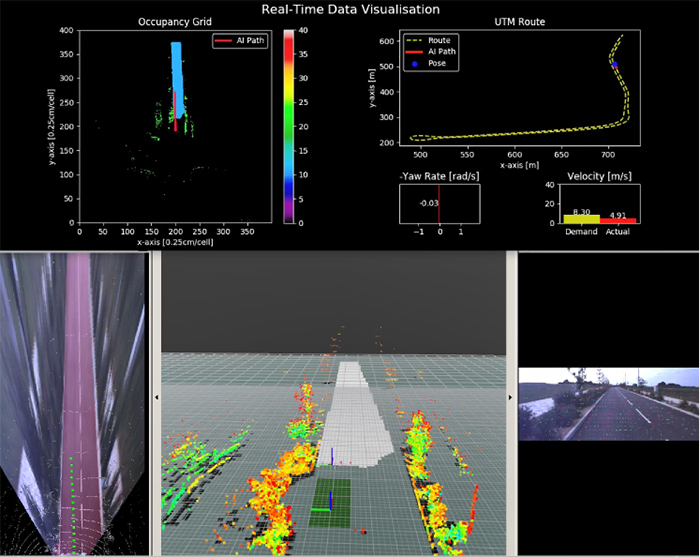
Figure 7: Software-in-the-Loop (SiL) and real-world testing for system verification
Our research and real-world experimentation of data-driven solutions for autonomous vehicles allowed us to identify some of the key benefits and limitations of this approach. Below we summarize the main lessons of this activity:
