9 June 2020

Manikandan Ravikiran
R&D Centre, Hitachi India Pvt. Ltd.
Video analytics solutions are typically a mix of multifaceted applications such as drones, robots, self-driving cars, safety surveillance systems etc. all of which require on-edge computation. Especially, with the rise of IoT solutions, there is need of lower memory AI systems on edge devices.
To accommodate this requirement, we developed an end-to-end automatic neural network memory reduction technology called “Multilayer Pruning Framework” that focuses on reducing memory and computation. We further validated the technology developed on multiple video analytics applications involving object detection and image classification to achieve up to 96% and 90% reduction in memory and computation, respectively.
Deep neural network exhibits two characteristics namely: (i) Presence of a large number of unused parameters which increases memory consumption (ii) Variety in architectures depending upon the end application.
Our proposed Multilayer Pruning Framework (Figure 1) is an end-to-end non-iterative unused parameter removal approach that exploits these characteristics where we hypothesize that identification and removal of the unused parameters would reduce the memory and computation and vary with neural network architecture.
Inline, with these hypotheses, our framework introduces following steps
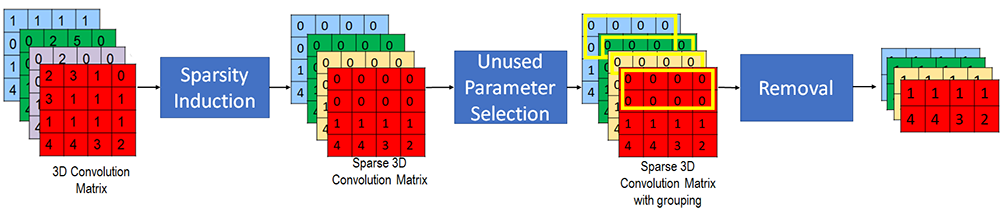
Figure 1: Illustration of proposed Multilayer Pruning Framework
1. Sparsity induction
Originally parameters in convolution layers are in form of 3D matrices (referred to convolution matrix from here onwards) where each element in matrix corresponds to a parameter value. A parameter value of zero indicates that it is unused and is removable. However, in many deep neural networks the unused parameters are scattered around the convolution matrix without any structure and some of the parameter have values very close to zero.
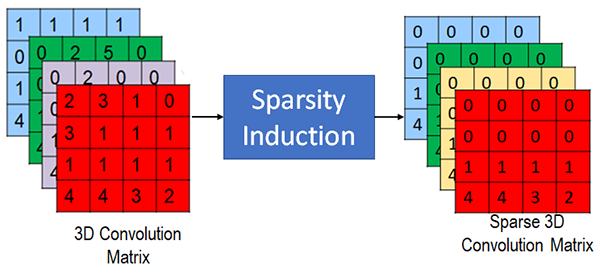
Figure 2: Sparsity Induction in convolutional matrices
To make sure unused parameters are organized in structured manner and to increase number of unused parameters by transferring capacity of parameters with values close to other parameters we introduce sparsity induction. Sparsity Induction (Figure 2) uses combination of methods which increases the unused parameters and enforces structure (grouping of zeroes) in convolutional matrix.
2. Unused parameter selection
Previously, we created a convolutional matrix with unused parameters. However, removing a single 0 from the matrix is not possible, instead we group a set of 0’s together across rows or columns. This results in creation of many such groups within the convolution matrix where all are zeros (Figure 3(a)) or majority of values are zero (Figure 3(b)).
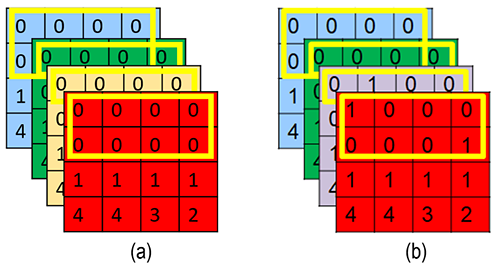
Figure 3: Sparsity in convolutional matrices having
(a) groups with all zero and (b) groups with majority zero
Using these rows or columns with zeroes, we designed a criterion called sparsity level which computes fraction of zeros present across the entire convolution matrix with respect to zero rows or columns. If this sparsity level is higher than a user-defined threshold, the entire convolution matrix will be removed. Thus, the user can set a threshold based on his/her memory requirements. If the threshold is low, more convolution matrix will be removed leading to more compression and vice versa.
3. Removal guidelines for various neural networks
In the previous steps, we introduced sparsity induction and unused parameter selection criterion. However, neural networks depending on applications have different types of layers and connections. As such we tested multiple approaches across classification and detection network, and this resulted in the following removal guidelines
Table 1 shows results of our approach with object detection network SSD300 [1]. Meanwhile, Table 2 shows results on image classification network [2]. We confirmed that our proposed method can produces high memory reduction and hence low processing cost across both.
Table 1. Benchmarking multilayer pruning framework for SSD300 on PASCAL VOC.
| Model | mAP | Number of Params | Model size (MB) |
|---|---|---|---|
| SqueezeNet SSD | 38.45 | 7 million | 28 |
| Resnet10 SSD | 64.83 | 6.7 million | 26.8 |
| Mobilenet SSD | 70.04 | 8.8 million | 35.2 |
| (Ours) | 75.07 | 3.9 million | 15.6 |
Table 2. Benchmarking multilayer pruning framework for VGG16 on CIFAR-10
| Model | Accuracy | Number of Params | Model size (MB) |
|---|---|---|---|
| Efficient Pruning | 93.4 | 190 million | ~100 |
| (Ours) | 94.01 | 1 million | 4.2 |
Finally, we believe our proposed approach has great potential in reducing the memory in variety of neural network architectures, thereby helping develop edge solutions with of lower powered AI systems. For more details, we encourage you to read our paper [3].
Thanks to my co-authors Pravendra Singh, Neeraj Matiyali and Prof. Vinay P. Namboodiri from IIT-Kanpur, with whom this research work was jointly executed.
*If you would like to find out more about activities at Hitachi India Research & Development, please visit our website.
