3 July 2020

Nestor Mariyasagayam
R&D Centre, Hitachi India Pvt. Ltd.
The digitization of hospital information systems has created a tremendous amount of health-related data. More particularly, electronic health records (EHRs) which contain valuable patient information are largely available in unstructured text format which cannot be analyzed easily without domain experts. Thus, there is a need to automate the extraction of precise and valuable information which can be then applied to various healthcare services such as assisting medical professionals, healthcare researchers, and patients.
To extract meaningful information from unstructured data especially in specialized clinical domains where there are many abbreviations, acronyms and medical jargons, it is relatively difficult when compared to simple conversations. The conversion of such complex unstructured data into meaningful information is key to opening several potential applications.
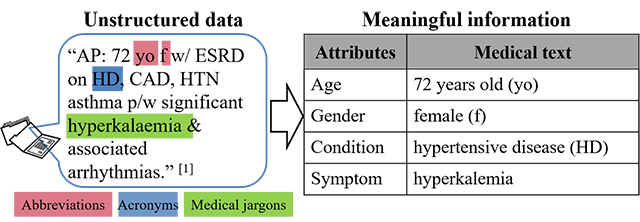
Figure 1. Unstructured data challenge: Example text extracted from ShARe/CLEF2014 [1]
Template filling is one of the ways to effectively extract complex information from a text. In our joint open innovation effort with IIIT-Hyderabad [2], we developed an information extraction technique that helps to understand the status of a disease or a disorder from a given set of de-identified medical reports. The status of disease/disorder (DD) relies on diverse aspects such as temporal information, body location, severity, and progression of the disease. We coalesce this information in the form of a template with ten different attributes adopted from ShARe/CLEF2014 eHealth 2014 Task 2 challenge [1] in which we had participated. As a result of such activity, we developed a system to extract the information of each of the medical attributes using machine learning-based approaches. Table 1 shows the list of attributes which we had targeted for our system development. These were based on the guidelines of the challenge.
Table 1. List of attributes targeted for extraction
| Attribute | What it indicates? |
|---|---|
| Negation Indicator | Whether a DD is negated |
| Subject Class | Who experienced the disease |
| Uncertainty Indicator | A measure of doubt into a statement |
| Course Class | Progress or decline of a DD |
| Severity Class | Severity of the DD |
| Conditional Class | Conditional existence under certain circumstances |
| Generic Class | Generic mention of a DD |
| Body Location | Represents an anatomical location |
| DocTime Class | Temporal relation between a DD and document authoring time |
| Temporal Expression | Represents temporal expression related to the DD |
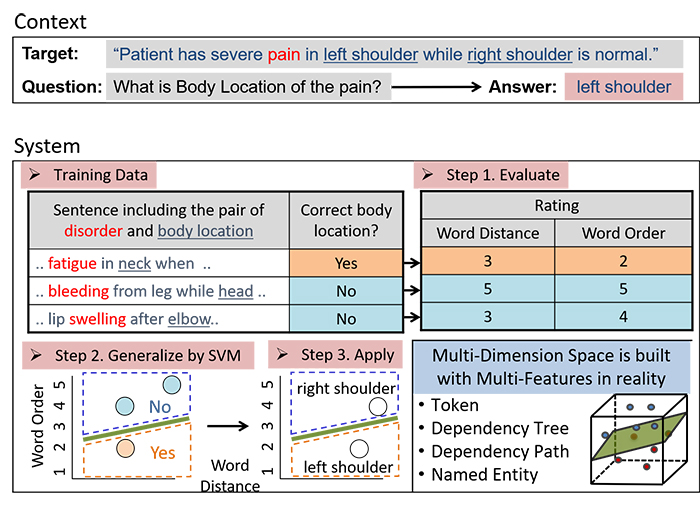
Figure 2. Our proposed information extraction process
We use the principle of Support Vector Machine (SVM) to illustrate one of the extraction components of our system that identifies the body location of the disease or disorder from a given clinical statement. Given a target and a question as shown in Figure 2, how one goes about finding the answer is explained illustratively. From a given set of training data which contains sentences including the pair of disorder and body location, in Step 1, we determine the relationship of the correct body location with respect to attributes such as word distance and word order within the corresponding sentence. Then by utilizing such attributes, in Step 2, we develop SVM model that classifies the body location with respect to the target disease or disorder. In Step 3, SVM model is applied to classify the target sentence and identify the location of the disease or disorder. There are more components involved in the extraction process and our end-to-end system accuracy on average was around 86.8%. For more technical details, readers are invited to refer to our detailed technical publication [2].
There are several potential applications which can arise out of information extraction. By properly leveraging clinical information mining, the system developed enables us to create data-center-based value-added services such as predictive diagnosis for early disorder detection, treatment recommendation for speeding-up recovery of patients and reducing patient load across healthcare network, and lifestyle-based advisory services for overall reduction of medical expenses of the society.
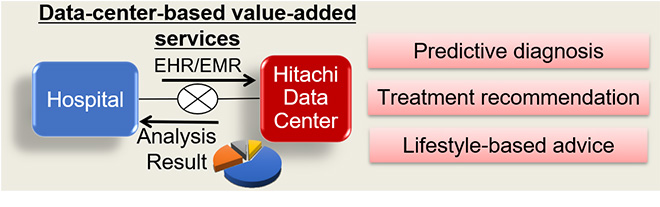
Figure 3. Potential applications
We wish to acknowledge and thank the authors from IIT-Hyderabad, and Hitachi, Ltd., Japan for the joint research activity and the achievement.
*If you would like to find out more about activities at Hitachi India Research & Development, please visit our website.
