11 December 2020

Shuai Zheng
R&D Division, Hitachi America, Ltd.
One of the main objectives of predictive maintenance is to predict and identify failures in equipment. This is typically done by monitoring the equipment and searching for any failure patterns. With the increased use of IoT devices, data-driven methods are increasingly being used to predict failures using large amount of sensor data collected from the system. To improve the accuracy of prediction however, requires sufficient samples of failure in the training data but represents a challenge as physical equipment and systems are engineered not to fail, thus failure data is rare and difficult to collect. In this blog, I’d like to talk about the Generative Adversarial Network (GAN) based approach to generate more samples to improve prediction result.
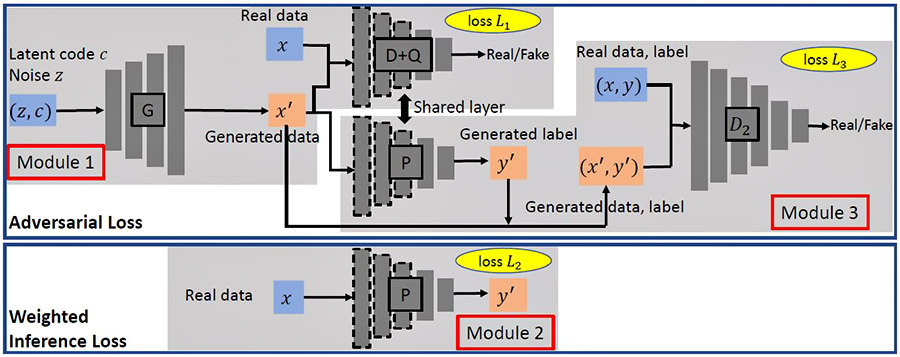
Figure 1: GAN-FP architecture
One problem with simply using existing GAN models, such as infoGAN, is that it cannot guarantee that the generated sample is from a desired class. This means that some generated samples might end up having the wrong label. For example, infoGAN is claimed to have 5% error rate in generating MNIST digits. When we have a 2-class highly imbalanced classification problem like failure prediction, this can have significant negative impact on the usefulness of this approach. In order to alleviate this problem, my colleagues and I proposed the use of a second GAN to enforce the consistency of data-label pairs. In the second GAN, we use the inference network P as a label generator.
Our model consists of three different modules, where module 1 and 3 are two GANs and module 2 is a weighted loss prediction network. Figure 1 shows the overall design of this model.
Module 1 adopts a GAN to generate class-balanced samples. We take infoGAN as an example. For the input categorical latent code c, we randomly generated labels 0s (non-failure) and 1s (failure) with equal probability. Network G is a deep neural network and outputs generated sample x'. Network D aims to distinguish generated sample x' from real sample x. Network Q aims to maximize the mutual information between latent code c and generated sample x'. By jointly training network G, D and Q, module 1 solves the minimax problem with respect to infoGAN loss function L1.
Module 2 consists of a deep neural network P and solves a binary classification problem with weighted loss based on real data and real label.
Module 3 is a GAN structure which consists of network P and D2 and enforces generated data-label pair (x', y') to look like real data-label pair (x, y). P serves as the generator network. D2 tries to distinguish the generated data-label pair from real pair. Loss L3 is a minimax objective for module 3.
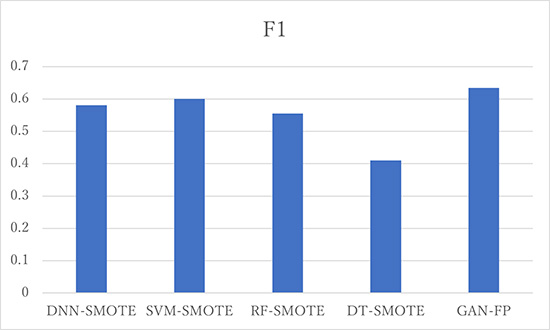
Figure 2: CMAPSS FD001 data F1 score comparision using different methods, GAN-FP is our method
Once the data is generated, a traditional approach would be to use both the generated and real samples to train a classifier. However, since we are sharing layers between the inference network and the discriminator network in the first GAN, and training all three modules simultaneously, we can directly use this inference network to achieve higher inference accuracy. We conducted experiments on one Air Pressure System (APS) data set from trucks and four turbofan engine degradation data sets from NASA CMAPSS (Commercial Modular Aero-Propulsion System Simulation). Figure 2 shows the result on one CMAPSS FD001 dataset, which only has one operating condition and one failure. GAN-FP is our approach. We compared it with different classifiers such as DNN, SVM, RF and DT. As we can see from the results, our approach performs the best on this dataset.
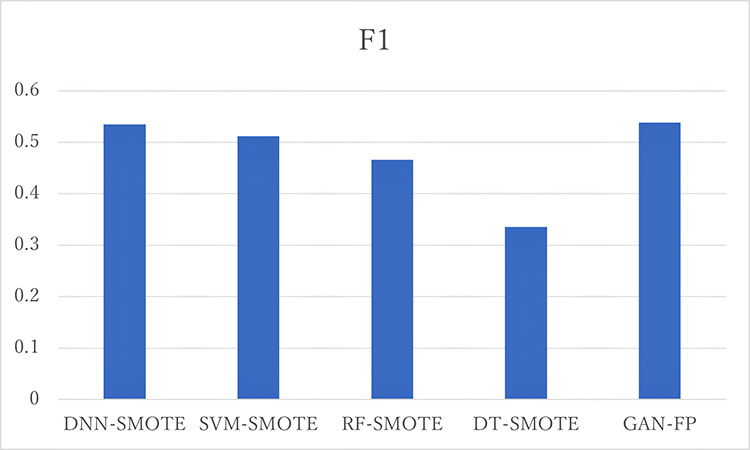
Figure 3: CMAPSS FD002 data F1 score comparision using different methods, GAN-FP is our method
Figure 3 shows the result for CMAPSS FD002, which has six operating conditions, thus this prediction task is more difficult. As we can see from Figure 3, in most cases, our approach GAN-FP gives better results.
For more details, please refer to our paper [1].
