18 December 2020

Dipanjan Ghosh
R&D Division, Hitachi America, Ltd.
Building trustworthy AI systems is of paramount importance with its growing use [1]. One of the tenets to building trustworthy AI is the need for AI models to consistently produce correct outputs for the same input [2]. Based on observations in field we realized that as we periodically retrain AI models, there are no guarantees that different generations of the model will be consistently correct when presented with the same input.
For example, consider a scenario of model re-training, as shown in Figure 1, of a vehicle repair-recommendation system where given required inputs, the system returns a correct output – 'replace E.G.R valve.' A month later once the model is retrained, for the same input information, the system returns an incorrect output – ‘replace turbo speed sensor.’ This can lead to a faulty or even fatal repair, thus reducing the reliability and users’ trust in the underlying AI model. Similarly, consider the damage that can be caused by an AI-agent for COVID-19 diagnosis that correctly recommends a true patient to self-isolate, and subsequently changes its recommendation after being retrained with more data.
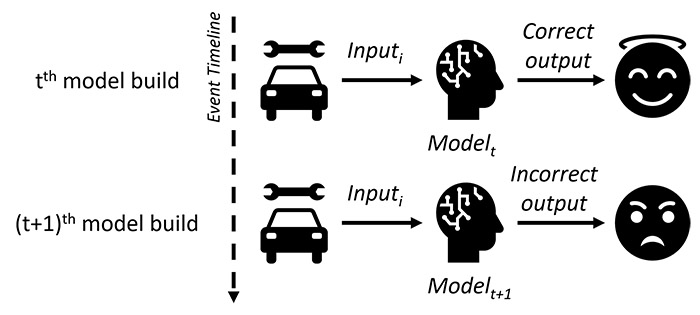
Figure 1: Model re-training consistency issue
In our research, we define consistency of a deep learning model as the ability to make consistent predictions for the same input across successive generations of the model. This definition is different from the replicability of model performance at an aggregate level [3] – with a stable training pipeline of a classifier, aggregate metrics can be relatively consistent across successive generations, but changes in the training data or even retraining with the same data often causes changes in the individual predictions. Consistency is applicable to both correct and incorrect outputs, however, the more desirable case is producing consistently correct outputs for the same inputs, and although mentioned in limited studies [4], no previous work has discussed or measured consistency formally.
We defined the ability to make consistent correct predictions across successive model generations for the same input as correct-consistency, and this month, we presented our work at NeurIPS 2020. In this work, we introduced metrics to measure consistency and correct-consistency as well as show why and how ensembles can improve consistency and correct-consistency of deep learning classifiers theoretically as well as empirically showed multiple desirable properties of ensembles related to consistency and correct-consistency:
Although the above properties clearly indicate that ensembles are a viable solution to address consistency and correct-consistency, building ensemble deep learning models is a computationally expensive procedure.
To address this challenge, we propose a dynamic snapshot ensemble (DynSnap) method with three main components: snapshot learning, dynamic pruning, combination methods (majority voting or averaging or weighted voting or weighted averaging). We have developed two variants of DynSnap – DynSnap-cyc and DynSnap-step, where good single learners of the ensemble are selected using a pruning criterion.
We applied the algorithm to three datasets – CIFAR10, CIFAR100 and YAHOO!Answers, where ResNet20, ResNet56 and fastText are the underlying base models, respectively. The objective of the experiments is to validate the theory as well as study the efficiency of the proposed DynSnap method.
The results shown in Figure 2 demonstrate that in general ensemble methods (ExtBagging, Snapshot, DynSnap-cyc, DynSnap-step) consistently outperform the methods with a single learner (SingleBase and MCDropout) for averaging (AVG) as the ensemble combination method. Similar results are obtained for other combination methods as well. Further, from Table 1 we can see that DynSnap greatly reduces the training time compared to ExtBagging with comparable predictive performance.
Thus, our method not only leads to improvement in accuracy, consistency and correct-consistency, but also achieves these objectives efficiently.
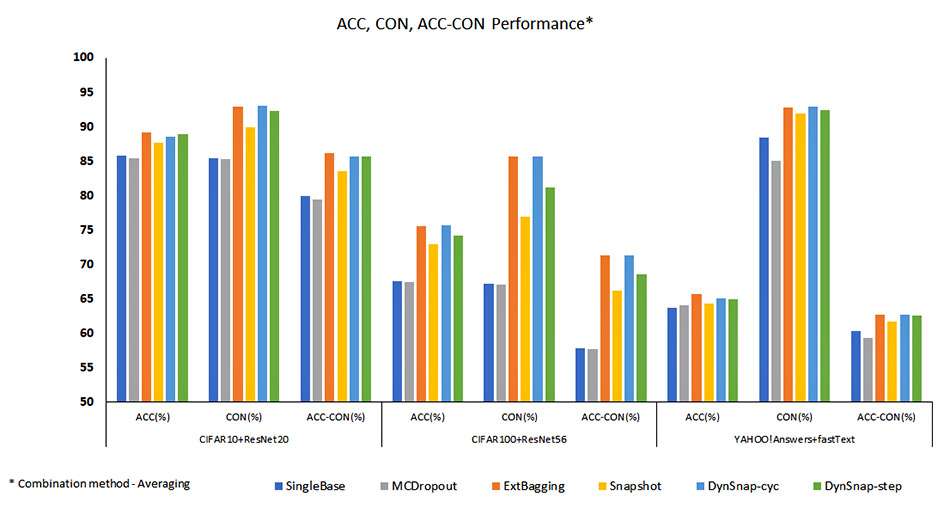
Figure 2: ACC, CON, ACC-CON performance
Table 1. Run-time of each method (k is one training time from scratch using the base model and model settings)
| Run-time (k) | CIFAR10+ResNet20 | CIFAR100+ResNet56 | YAHOO!Answers+fastText |
|---|---|---|---|
| SingleBase | k1 | k2 | k3 |
| ExtBagging | 20 * k1 | 20 * k2 | 20 * k3 |
| MCDropout | k1 | k2 | k3 |
| Snapshot | 2 * k1 | 2 * k2 | 2 * k3 |
| DynSnap-cyc | 3 * k1 | 4 * k2 | 5.3 * k3 |
| DynSnap-step | 7 * k1 | 5.3 * k2 | 5.3 * k3 |
This study can have a major impact on applications of prognostics, recommendation engines, visual inspection where users’ trust in the AI system can be increased. We recommend that data scientists and delivery teams consider consistency and correct-consistency as additional metrics to be optimized before production deployment.
For more details, we encourage you to read our paper, "Wisdom of the Ensemble: Improving Consistency of Deep Learning Models" which was presented at the 2020 Conference on Neural Information Processing Systems (NeurIPS).
