10 May 2021

Naoyuki Terashita
Research & Development Group, Hitachi, Ltd.
Expanding applications [1, 2] of generative adversarial networks (GANs) makes improving the generative performance of models increasingly crucial. An effective approach to improve machine learning models is to identify training instances that “harm” the model’s performance. Recent studies [3, 4] replaced traditional manual screening of a dataset with “influence estimation.” They evaluated the harmfulness of a training instance based on how the performance is expected to change when the instance is removed from the dataset. An example of a harmful instance is a wrongly labeled instance (e.g., a “dog” image labeled as a “cat”). Influence estimation judges this “cat labeled dog image” as a harmful instance when the removal of “cat labeled dog image” is predicted to improve the performance (Figure 1)
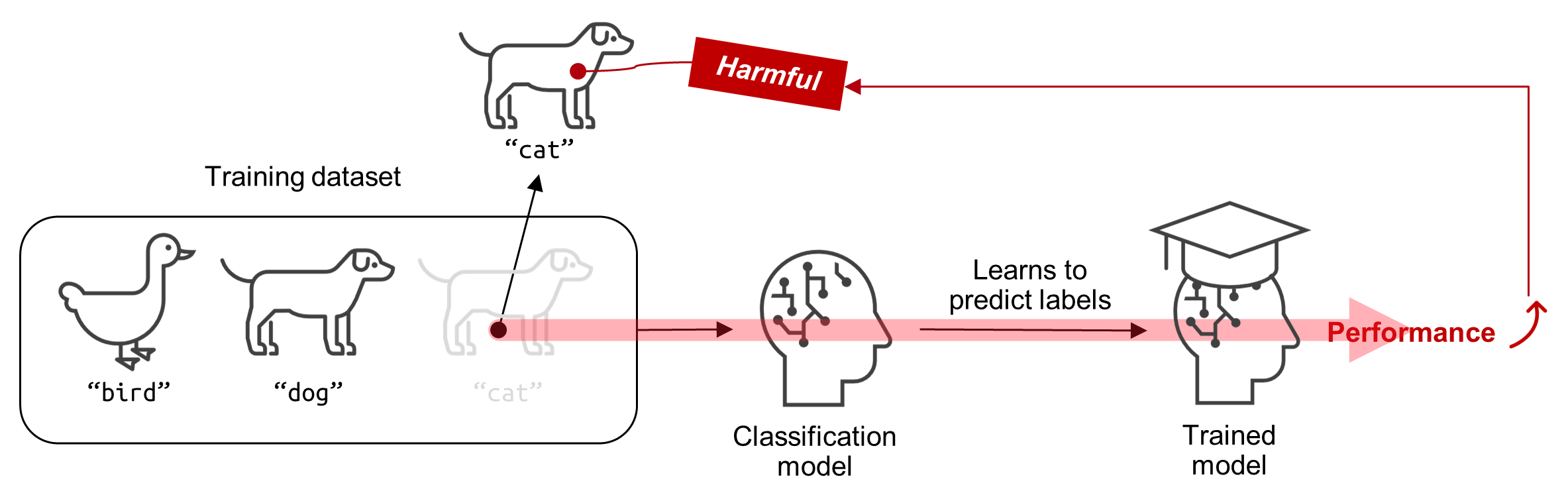
Figure 1: Example of a harmful instance in supervised learning
Previous studies have succeeded in identifying harmful instances in supervised learning, such as a classification task. Supervised learning is normally a one-model setting, in which there is a single model and thus the absence of a training instance directly affects the model. Extending previous approaches to GANs is not an easy task because GANs are trained on two-model settings; a generator tries to generate realistic samples and a discriminator tries to correctly classify whether the samples are real or generated or real. The training instances are thus only fed into the discriminator and they “indirectly” affect the generator (Figure 2).
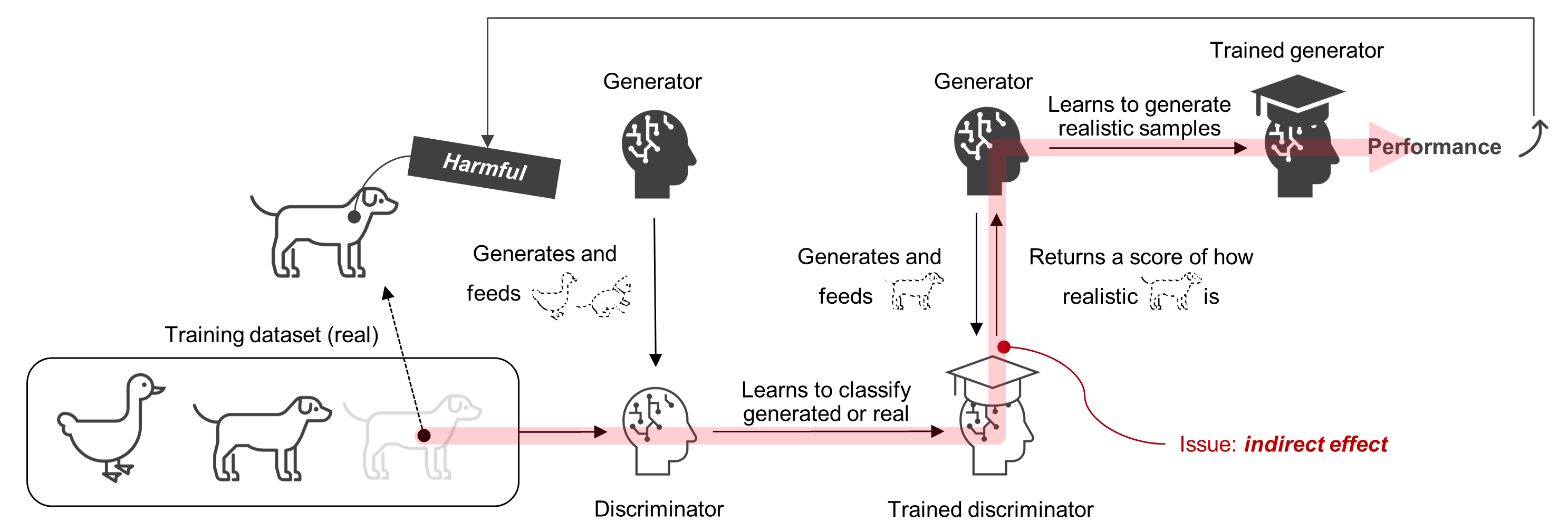
Figure 2: A major issue “indirect effect” of influence estimation for generative adversarial networks.
To solve this problem, we proposed a novel influence estimation method that uses the Jacobian of the gradient of the discriminator's loss with respect to the generator’s parameters (and vice versa) to trace how the absence of an instance in the discriminator’s training affects the generator. We also proposed to evaluate the harmfulness of an instance by estimating how a GAN evaluation metric is expected to improve when the instance is removed. We named this measure of the harmfulness “influence on GAN evaluation metric”.
The removal of suggested harmful instances based on “influence on GAN evaluation metric” was evaluated to see how it improved the performance of the generator. We tested two datasets: 2D multivariate Gaussian (2D-normal) and MNIST. Harmful instances in 2D-normal are identified based on influence on average log-likelihood (ALL). For MNIST, we estimated harmful instances based on influence on inception score (IS) [5] and Fréchet inception distance (FID) [6]. For both setups, instances were selected using baseline approaches: anomaly detection (Isolation Forest), influence on the discriminator loss (Disc. Loss), and random selection (Random). Figure 3 shows the average test GAN evaluation metrics across the repeated experiments with respect to the number of removed samples for each selection approach. For all the settings, our data cleansing approach statistically significantly improved the GAN evaluation metrics, showing higher performance compared to the baselines.
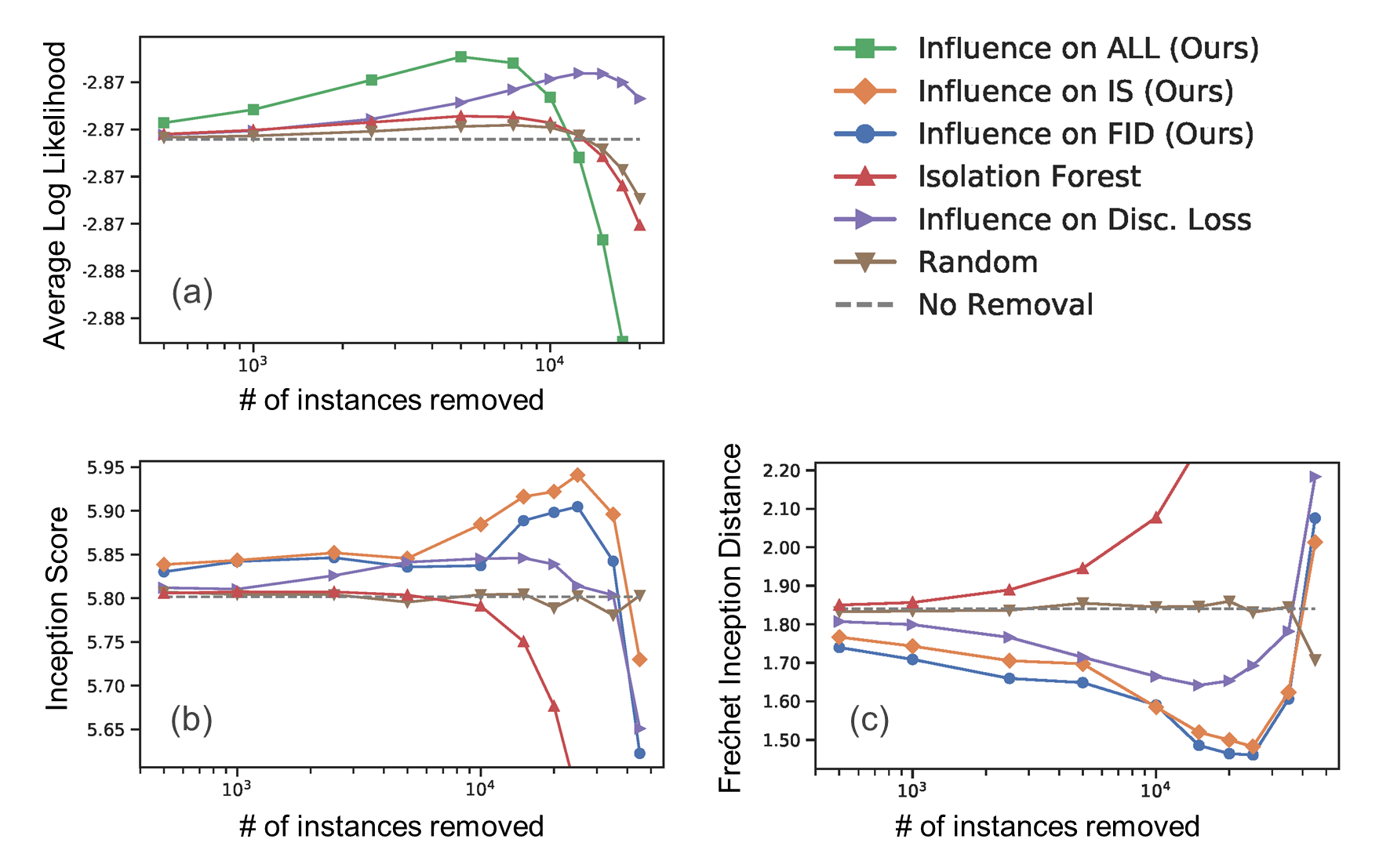
Figure 3: (a) Average log likelihood (ALL), (b) Inception score (IS), and (c) Fréchet inception distance (FID) evaluated with a test dataset and latent variables after data cleansing. The larger values for ALL and IS, and a smaller value for FID indicate better generative performance.
We also examined the characteristics of harmful instances. Overall, harmful instances were found to belong to regions from which the generator sampled too frequently compared to the true distribution (Figures 4a and 5a). Removing those instances alleviated over sampling which moved the generator distribution of 2D-Normal closer to the true distribution in Figure 4b, and the generated MNIST samples changed from the image of digit 1 to that of other digits after data cleansing (highlighted samples in Figures 5b and 5c).
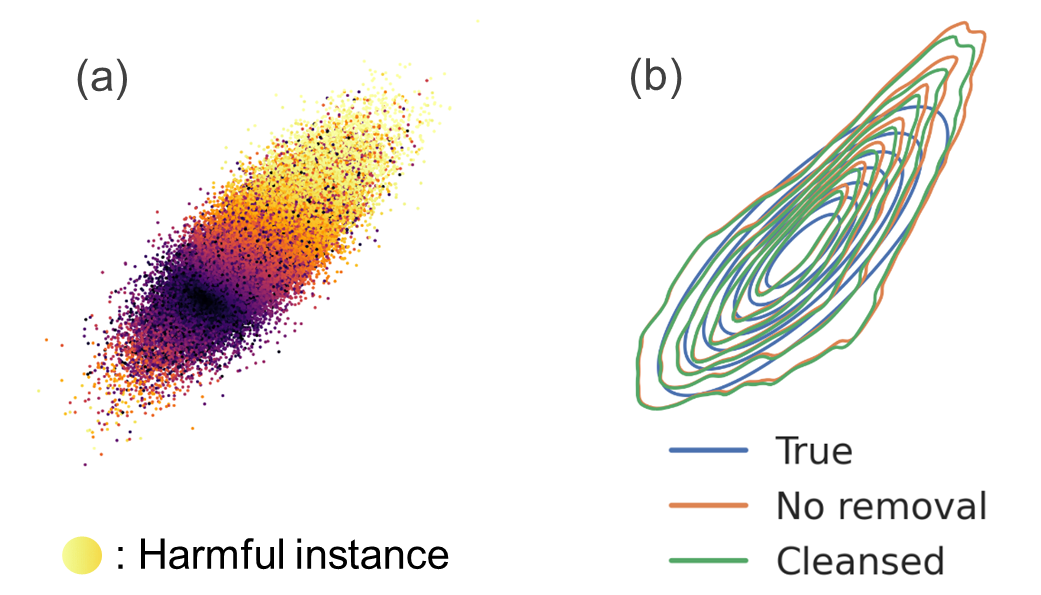
Figure 4: Harmfulness of 2D-normal instances illustrated using (a) influence on ALL and (b) changes in the generator's distribution. (b) includes plots of the true distribution (True) and generator's distributions before (no removal) and after data cleansing (cleansed).

Figure 5: (a) top 36 harmful MNIST instances predicted based on influence on FID, and the test generated samples (b) before and (c) after data cleansing.
This is the first research that enables influence estimation in GANs. Our proposal has the potential to not only improve generative performance but also provide an important scope of the interpretability of the training dynamics of GANs. For more details, we encourage you to read our paper, "Influence Estimation for Generative Adversarial Networks" which was presented at The Ninth International Conference on Learning Representations (ICLR 2021) on 4 May 2021.
