26 May 2021

Masato Tamura
Research & Development Group, Hitachi, Ltd.

Tomoaki Yoshinaga
Research & Development Group, Hitachi, Ltd.
The person re-identification (Re-ID) task aims to associate images of the same person across multiple non-overlapping camera networks. Re-ID models typically extract whole body features from images of people and match the features via proper distance metrics. Because of this approach, Re-ID-based video surveillance systems can track people without personal information such as faces, and hence effective for the systems. Following the success of deep convolutional neural networks (CNNs) in many computer vision tasks, CNNs have become de-facto standard for Re-ID models. CNNs can extract important clues to identify people from images, and as a result, achieve more than 95% of the identification accuracy. [1]
While the performance is extremely impressive, the method still has a significant problem for practical use. Currently, the high accuracy is achieved only in the in-domain setting, where CNNs are trained with images from one domain (e.g., captured with cameras of a same model in a facility), and evaluated with those from the same domain. In practical video surveillance systems, however, performance in cross-domain settings is crucial as the systems are typically deployed in various scenes without re-training the CNNs. It is also widely known that identification accuracy is significantly degraded in the cross-domain settings, and this phenomenon has been observed in our video surveillance system as well. To overcome this problem, we’ve been looking at how to create Re-ID models that can achieve high performance universally without the re-training, i.e., generalizable Re-ID models. We presented our method to improve the generalization capability of Re-ID models at the British Machine Vision Conference 2020 (BMVC2020). In this blog, we outline our method but if you’re after a little more detail, we recommend that you read the paper which can be found here.[2]
To improve the performance of generalizable Re-ID models, we focused on the biased example problem. Typically, generalizable Re-ID models require large-scale training data for the generalization power. Because of the scale, the data contain a large number of biased examples. Here, “biased” means that the statistics of examples is significantly discrepant with those of common ones. These examples degrade the performance of Re-ID models. The left part of Figure1 shows those examples. The images above are common examples, and the images below are biased examples. As shown in the examples, a valid training image typically captures the whole body of a target person, while a biased image is problematic because it may contain a target person which is highly occluded, partial, or even absent. To extract identifiable features from these biased examples, Re-ID models are likely to over-fit to them during the training. In other words, models learn to extract example-specific features to fit those biased examples. Such learning process may render the features extracted from common examples useless. Since the number of biased examples in large-scale training datasets is non-negligible, they degrade the generalization performance.

Figure 1: Overview of proposed soft-label regularization. Soft labels are generated by a model with a trained feature extractor and a classifier trained at the early stage of learning. This beginner classifier enables the generator to assign low-entropy labels to common examples and high-entropy labels to biased ones. Using these labels as regularization mitigates the performance degradation caused by biased examples.
To mitigate the impact of biased examples, we leveraged a teacher-student optimization method. As shown in Figure 1, this method has a label generator and Re-ID model, which are simultaneously trained. The label generator acts as a teacher that regularizes the Re-ID model, while the Re-ID model acts as a student that identifies target people. The key components of this method are an expert feature extractor and a beginner classifier in the label generator. The expert feature extractor is based on a CNN, which is resistant to over-fitting, while the beginner classifier is composed of fully connected layers, which is prone to over-fitting. To prevent the over-fitting of the classifier, we force it to stay in an early stage of learning by periodically initializing the learned parameters. As a consequence of combining the feature extractor and the classifier, the label generator identifies people having common images with high confidence and those having biased images with low confidence. These example-dependent outputs are used as ground truth labels to train the Re-ID model. Due to the nature of the cross-entropy loss, which is used to train the Re-ID model, examples with high-confident labels are more focused compared to those with low-confident labels, and as a result, the negative impact of biased examples are reduced.
In the following section, we will show the evaluation results of our method.
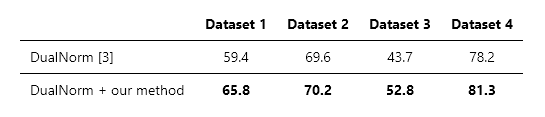
To confirm the effectiveness of our method, we compared the performance with the current state-of-the-art generalizable Re-ID model, DualNorm [3], on four datasets. Table 1 shows the comparison results of the identification accuracy. As shown in the table, our method improves the performance of DualNorm on all the four datasets. In particular, the accuracy is improved by 6.4 points in Dataset 1, which is significant improvement for Re-ID. These results indicate that our method is effective generally, and hence useful for creating practical video surveillance systems.
Table 1: Comparison results.
In this blog, we presented our method for improving the performance of generalizable Re-ID models. Since the re-training of CNNs incurs huge labor costs, the generalization performance is crucial to create widely deployable video surveillance systems. The experimental results show that our method improves the performance, and hence contributes to create practical video surveillance systems. For more details on our method, the full paper [2] can be found on the 31st British Machine Vision Conference website.
