22 February 2022

Yuta Koreeda
R&D Division, Hitachi America, Ltd.
Reviewing a contract is a time-consuming procedure. A study by the Exigent Group in 2019 [1] revealed that "60-80% of all business-to-business transactions are governed by some form of written agreement, with a typical Fortune 1,000 company maintaining 20,000 to 40,000 active contracts at any given time." This represents a significant cost for many companies as contract review is currently a manual process by trained professionals. For small companies or individuals who may have limited resources, this may mean that they have little choice other than to sign contracts without access to such professional services.
As part of our longstanding collaboration with Stanford University, we started to look at how we could use natural language processing (NLP) to tackle such a problem in 2020. Through this collaboration, we came up with the idea of formulating contract review automation as a natural language inference (NLI) problem, a classic, fundamental problem in linguistics. Specifically, given a contract and a set of hypotheses (such as "Some obligations of the agreement may survive termination."), we classify whether each hypothesis is “entailed by”, "contradicting to” (false) or “not mentioned by” (neutral) the contract and identify evidence for the decision as spans in the contract (Figure 1). This would allow users to “test” incoming contracts against their policy (e.g., raise an alert on contracts that entail "Some obligations in the Agreement may survive termination."). The same idea could be used for other Legal and RegTech problems, such as testing requirements (hypotheses) against documents in due diligence.

Figure 1. Overview of our ContractNLI task
In this blog, I’d like to share an overview of our work. To find out more about the technical details, please read our recent publication at the Findings of EMNLP 2021 [2].
Since no data exists that embodies our idea, we started by creating the dataset, which turned out to be a complicated process. We collected public documents from Electronic Data Gathering, Analysis, and Retrieval system (EDGAR) and other data sources, and from more than 12 million documents collected, we extracted 607 non-disclosure agreements (NDAs) with rules and some manual screening.
Another problem that we encountered was that most of the NDAs were visually structured documents like PDFs. These documents needed to be preprocessed in order to be fed into any machine learning system. Therefore, we developed a new tool for extracting clean text from PDF and other visually structured documents [3]. The tool has been open-sourced. We then annotated all 607 NDAs through consultation with attorneys and paralegals. This resulted in ContractNLI, the first dataset to utilize NLI for contracts as well as being the largest corpus of annotated contracts. Like the preprocessing tool, we open-sourced ContractNLI so that the community can work together to pursue state of the art in LegalTech. LegalTech.
Over the last couple of years, Transformer-based deep learning models [4] have become a dominant approach in NLP. Unlike traditional recurrent neural networks that sequentially process each token, Transformer calculates interactions over all pairs of input words, and thus yields a rich representation of meaning at a cost of scalability to longer inputs (because computation grows quadratically to the length of input). Previous works have also implemented evidence identification on the Transformer architecture by predicting start and end words, scaling it to a document by splitting the document into multiple contexts with a static window and a stride size [5,6] (Figure 2; SQuAD BERT). The start/end word prediction makes the problem unnecessarily difficult because the model needs to solve span boundary detection and evidence identification concurrently, whereas the definition of spans is usually fixed for many applications. Splitting a document can be problematic when a span is split into multiple contexts or when a span does not receive enough context.
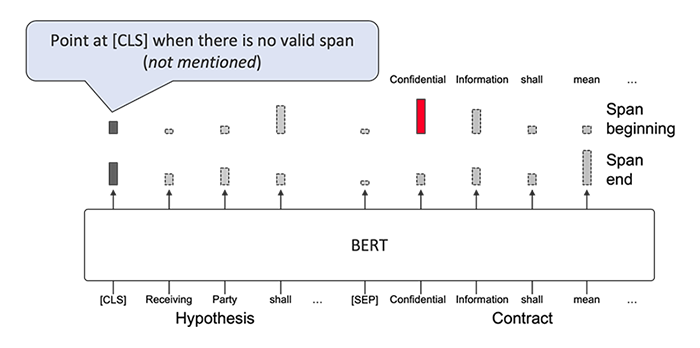
Figure 2. Transformer-based span identification in previous works (SQuAD BERT)
To address these issues, we developed Span NLI BERT, a multi-task Transformer model that can jointly solve NLI and evidence identification, as well as addressing the above shortcomings in the previous works (Figure 3). Instead of predicting start and end words, we proposed to insert special [SPAN] tokens each of which represents a span consisting of subsequent words and model the problem as straightforward multi-label binary classification over the [SPAN] tokens. We also proposed to split documents with dynamic stride sizes such that there exists at least one context setting for each span in which the span is not split and receives enough context.
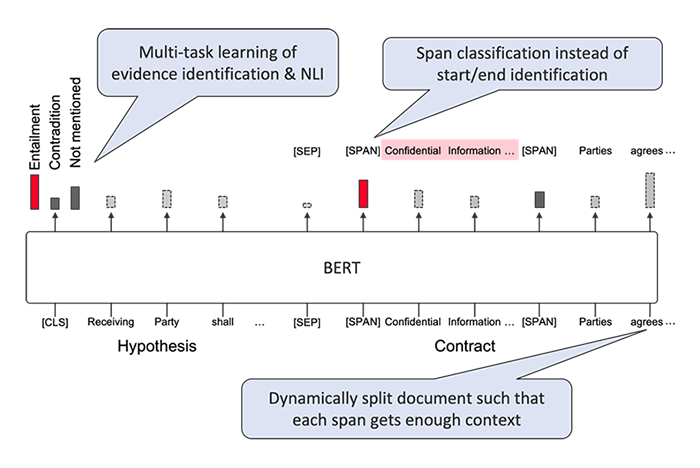
Figure 3. Our multi-task Transformer model that jointly solves NLI and evidence identification (Span NLI BERT)
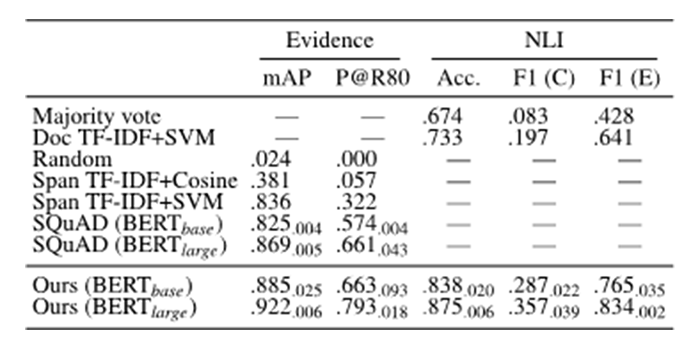
We compared our Span NLI BERT against multiple baselines including SQuAD BERT explained above. As you can see in Table 1, Span NLI BERT performs significantly better than other baselines. Nevertheless, the F1 score for contradiction label (F1 (C)) is not so impressive and we believe there is still much room for improvement. In fact, we found that we could significantly improve NLI if we can improve the evidence extraction part of the system. We also showed that the linguistic characteristics of contracts, such as negations by providing exceptions, contribute to the difficulty of this task (see our paper [2] for details).
Table 1. Main results
As part of our collaboration with Stanford University, we looked at how we could apply NLP to help automate the contract review process, where we found contract review to be a challenging real-world use case of NLI. As part of the work, we developed and open-sourced a preprocessing tool and a corpus of contracts. We also developed Span NLI BERT, a new competitive model for ContractNLI which we hope to be a starting point for developing better systems for ContractNLI.
The author would like to thank co-author Christopher D. Manning for his contribution in this research work. We used the computational resource of AI Bridging Cloud Infrastructure (ABCI) provided by the National Institute of Advanced Industrial Science and Technology (AIST) for the experiments.
