18 March 2022

Hang Liu
Research & Development Group, Hitachi, Ltd.
AGVs (automated guided vehicles) have been a staple in material handling industries such as manufacturing and warehousing where they can increase productivity, reduce labor costs, and improve safety. Customer demand for faster delivery and lower costs is driving a transformation in these industries for higher efficiency and throughput. One of the most important technologies for AGV systems is unmanned navigation technology, which allows such mobile robots to achieve incredible levels of performance [1]. Choosing the right vehicle navigation technology is critical since it will affect the performance of the whole AGV fleet.
In traditional operating models, a navigation system completes all calculations i.e., the shortest path planning in a static environment, before the AGVs start moving. However, due to constant incoming offers, changes in vehicle availability, etc., this creates a huge and intractable optimization problem [2]. Meanwhile, an optimal navigation strategy for an AGV fleet cannot be achieved if it fails to consider the fleet and delivery situation in real-time. Such dynamic route planning is more realistic and must have the ability to autonomously learn the complex environments. Deep Q network (DQN), that inherits the capabilities of deep learning and reinforcement learning, provides a framework that is well prepared to make decisions for discrete motion sequence problems [3].
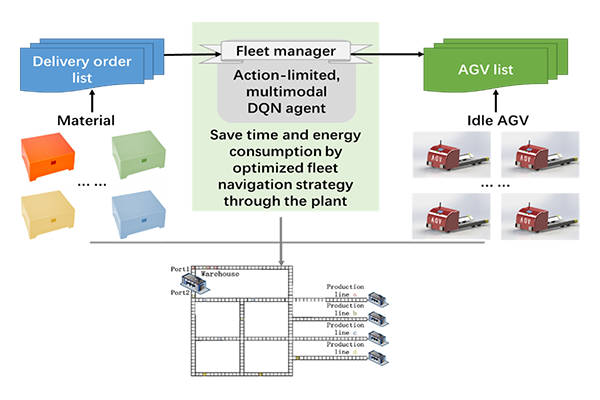
Figure 1. Workflow of the proposed method for AGV fleet route planning
For actual application, we improved the DQN structure into a model with a more efficient and generally practical update method for the network parameters according to the actual roads and specific delivery demands (Figure 1). Specifically, for the general applicability aspect, the DQN architecture should be equipped with output nodes of all mechanical feasible actions of a vehicle, however, not all actions are feasible for certain road (route) conditions. In this case, when calculating the loss function, we do not only consider the error in the direction towards the optimal strategy, but also limit Q outputs of some nodes, i.e., certain Q values would be bound to zero when they are corresponding to completely infeasible actions under current road condition. This improvement allows the network to focus learning on feasible actions. Moreover, when state data of multiple sources is accessible, such as data from web cameras on the route, positioning system, etc., multimodal DQN can propose a better planning by pooling the decision learned from different unimodalities [4]. The output of each unimodal learning will be represented by suggestions indexes of all actions, and trust indexes in each unimodality will help us determine the final choice.
The performance comparison among multimodal and unimodal learning, as well as multimodal learning of the action-limited DQN and the general multimodal learning is shown in Figure 2 below. The multimodal learning combines input data of two modalities which comes from positioning devices installed on each vehicle and surveillance cameras placed on the site routes. The multimodal learning is achieved by fusing the unimodal learning, it is necessary to determine the trust index of them. According to the unimodal learning result, the learning results of modality 1 gives better route planning performance than modality 2, where we give the former a high trust index in a smaller scale. Finally, the action-limited loss function improves route planning further, so the proposed method can give a performance on the overall time consumption.
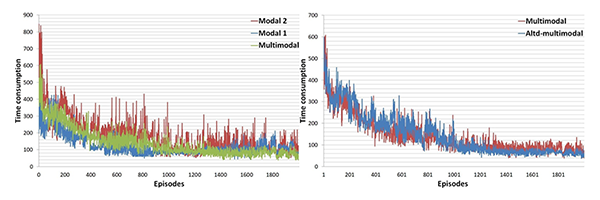
Figure 2. Performance evaluation of the proposed method
Applying our proposed optimization algorithm, a better AGV fleet route planning can be achieved. The action-limited Q function is proposed to bound the unfeasible action to guide a more focused learning, which is realized by redesign the calculation of the loss function, while a multimodal learning fuses the decisions through the recommended value and trust indexes given by each unimodal learning. The optimization performance can be further increased in the combination of the action-limited and multimodal learning.
For more details, we encourage you to read our paper [5].
Acknowledgements
Many thanks to my colleagues, Akihiko Hyodo, Akihito Akai, Hidenori Sakaniwa and Shintaro Suzuki with whom this research work was jointly executed, and supported me in preparing this blog article on our paper.
