1 June 2023

Yasushi Miyata
Research & Development Division
Hitachi America, Ltd.
Data is the new “oil” in driving the digital economy. It has the potential to give industries a competitive business advantage. But, data, like oil, also needs to be refined for its intended use. My colleagues and I have been working on AI technology that can accelerate business by refining data, especially under-utilized data-embedded documents, at a low cost. Let me explain.
AI can help organizations save time completing certain tasks. Banks, for example, can use AI to scan through a plethora of financial statements and annual reports when researching loans and investments. AI helps them find key information and store it in their knowledge base for further analysis. Banks encounter problems, however, when these statements and reports come in different formats. This is when automation tends to fall short of its full potential. In such cases, AI needs the ability to identify different formats as well as have the domain knowledge to decide what is important.
This challenge around data extraction can be approached in two ways. One is the deep-learning approach. The model in this approach collects different kinds of documents and labels their ground truths. One example of this is the LayoutLM [1] model which is familiar with various published formats. Another approach is a rules-based model, whereby AI familiarizes itself with format types and the relative information positions within each format.
Both approaches have their weaknesses: they cannot extract information from new or updated types of documents. Neither is fine-tuned enough to be aware of minor changes and updates to formats, and thus can be prone to extraction errors which can be costly down the line. The challenge, therefore, becomes training the AI model to extract information from new or unfamiliar formats.
Our state-of-the-art model teaches itself to read information from rich formatted texts. We are employing new ways to denote information located in the document by using multiple axes to indicate placement. Figure 1 below displays three extraction examples showcasing this greater adaptability.
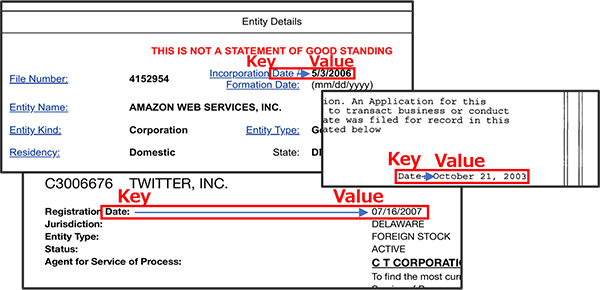
Figure 1. Examples of data extraction based on a date formatting rule
This aids in the extraction of information from new or unfamiliar formats. One challenge we face is the sheer variety of formatting rules. The other is that rules may differ from format to format. Snorkel [2] and Fonduer [3] can help solve the consistency issue across formats. We are working on automatically generating formatting rules using a self-learning technique as we speak.
AI learns the ground truth as training data. But preparing training data takes significant time and effort. So, we proposed self-supervised formatting rules for learning. The AI finds formatting rules to be observed as training data on its own, using ground formatting rules and ideas to determine what data type should be extracted.
The Value is the information the customer seeks. The Key is the marker when searching for the value. The relationship between the Key and the Value is necessary to find the Value. Observing these relationships, we established nine Ground Formatting Rules.
In Figure 1, note that the actual date is on the same row and to the right of “Date.” The reader’s eyes go to “Date” first, then finds the actual Value. In other words, in this case, the Key is “Date,” and the relationship between the Key and Value is “to the right and on the same row.” So, one of the Ground Formatting Rules is “[Value] is the [Relation: Position] of the [Key].” The Position can include general directions, such as left or right, or can indicate that the Value in question is generally placed before other marker words, like “Inc.” or “Ltd.” Sometimes the Key is the entire page. When this happens, the document describes the author, title, date, etc.
As mentioned, in order to save on time and labor, we trained an AI to engage in self-supervised learning by examining frequently used formats. Sometimes, certain formats cannot serve as training data because of overlapping but irrelevant markers. In these cases, we must refine our data extraction format as described in Figure 2 below.
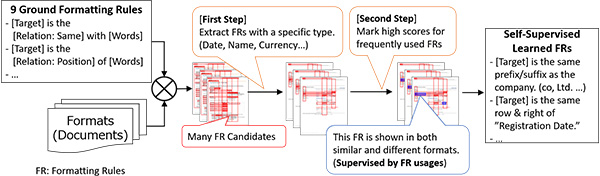
Figure 2. Self-supervised learning of formatting rules by usage
The first step, “Simple Refinement,” identifies target values by the data type. For example, when extracting financial information, the data will be a type of monetary value. If the value type does not match the target type, the refinement marks it as “False.” Often, when extracting a company name, the Value will include an upper-case letter.
The second step is to look at words that recur across formats and determine whether they are relevant. Some words that are versatile across formats would be “Type,” “Name,” and “Value.” We observed whether they are meaningful by scoring them on how often they co-occur within different and similar formats. If a certain word co-occurs within only different formats, the word is meaningless because similar formats, composed of the same formatting rules, might not use the word as part of their formatting rule. If a meaningful formatting score is high, we can mark these as “True” keys to the format. This was performed as self-supervised learning. This learning manner, including rule-based self-generation of ground truths, is called self-supervised learning.
We looked at a number of different types of formats, including corporate reports, municipal registration, and medical records, and established nine ground formatting rules. Using these ground rules, we generated 31 formatting rules using company names and registration dates, and statuses after having the self-supervised AI look at 114 documents.
Two typical examples are shown in Figure 3.

Figure 3. Example of extracting company name and registration date
We could extract the company name — in some cases made easier by the inclusion of “INC.” We could also extract the company’s registration date by using the usual position of these dates.
Table 1 presents the number of Formatting Rules (FR), the coverage of those rules, the number of days taken to design those rules and the accuracy of the information extracted. FR at 31, increased markedly compared to manual analysis at 19. The precision within the extraction was also improved. In other words, although the number of correct answers is about same (Recall) because precision has improved, the rate of false positives has decreased.

Table 1. Example results from extracting workday information
Establishing a self-supervised learning approach for an AI to familiarize itself with existing document formats proved to be a novel and successful approach. While it can obviously save on costs compared to solutions involving manual labor, more importantly, it frees up the time so that humans can focus on finding real and new value in the under-utilized data they have. An added advantage is that this self-supervised learning approach can be trained by non-experts. As a result, under-utilized data-embedded documents can be refined to become a differentiating source accelerating business and contributing to a competitive edge.
This work was conducted under the Stanford Data Science Initiative (SDSI). I would like to thank Chris Ré’s laboratory members for making this work possible: Sen Wu, Luke Hsiao, and Chris Ré.
