22 March 2024

Terufumi MORISHITA
Research & Development Group
Hitachi, Ltd.
Recent large language models (LLMs) have shown to be able to skillfully solve a wide range of tasks, foreshadowing the realization of artificial intelligence (AI) as "a machine that thinks like humans”[1]. To realize such AI, two elements have long been considered important: knowledge and reasoning.[2-7] In the context of natural language processing, “knowledge” refers to a collection of facts about the world, such as “things with mass generate a gravitational field” and “the Earth has mass.” On the other hand, “reasoning” is a form of thinking that combines multiple pieces of knowledge according to certain rules to gain new knowledge. For example, by applying the reasoning rule ∀x F(x)→G(x),F(a) ⇒ G(a) (F=”has mass”, G=”generates a gravitational field”, a=”Earth”) to the aforementioned knowledge, we can gain new knowledge that “the Earth generates a gravitational field.”
Recent observations suggest that LLMs solve tasks primarily by analogy from existing knowledge rather than pure reasoning. [8-10] For instance, observations such as “being able to solve coding tests from past years but not the latest year” or “being able to solve famous arithmetic problems as they are, but not when the numbers are changed” imply that what seems like “reasoning” may actually be retrieving knowledge “memorized” during pre-training. This knowledge bias exists even in state-of-the-art LLMs like GPT-4. [11-14]If LLMs struggle with reasoning, this poses a challenge for the realization of generalizable AI that can solve problems truly unknown to humans, because knowledge can solve only tasks “that have been seen before.” To achieve generalizable AI, we need to pursue further research to improve the “reasoning capabilities” of LLMs.
This blog introduces one such approach taken by my colleagues and I which we presented at ICML 2023. Our approach was to teach LLMs logical reasoning using many synthetically generated training examples. Specifically, we proposed a framework named FLD (Formal Logic Deduction), which generates diverse patterns of deductive reasoning examples, as illustrated in Figure 1, based on formal logic theory. Given a set of facts and a hypothesis, an LM is required to generate proof steps to (dis-)prove the hypothesis and an answer.
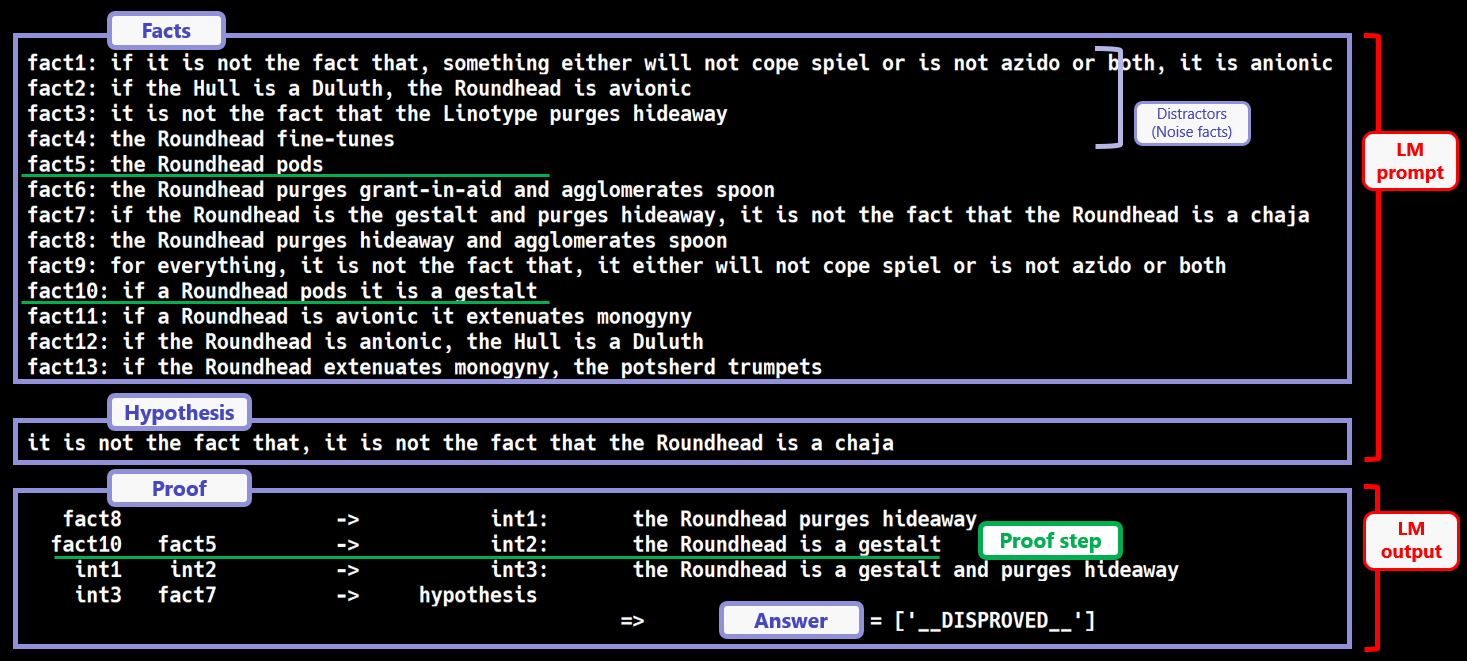
Figure 1. A deduction example generated by FLD. Examples of deductive reasoning. Note that the facts are randomly constructed except logical structures (i.e., they have no semantics) so that referring to existing knowledge never helps solve the task
We first investigated how well current LLMs, such as GPT-4 solves logic, specifically deductive reasoning problems, and found that even GPT-4 can only solve about half of the problems, suggesting that pure logical reasoning isolated from knowledge is still challenging for LLMs. Next, we empirically verified that training on FLD was effective in acquiring robust logical reasoning ability. The FLD corpora and code can be found on here on github, and serve both as challenging benchmarks and as learning resources.
To consider how we should design the logical corpus, we first looked into the formal theory of logic, also known as symbolic logic or mathematical logic. We then considered the following single-step deductive reasoning:

This deduction step derives the conclusion, written under the bar, from the two premises.
We can abstract Eq. (1) using symbols as:
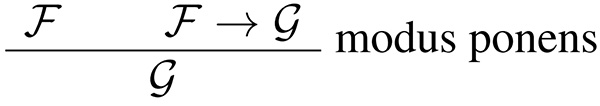
The deduction step of this form is called, modus ponens.
While modus ponens is the most intuitive deduction step, many others exist.
For example, a famous syllogism is:
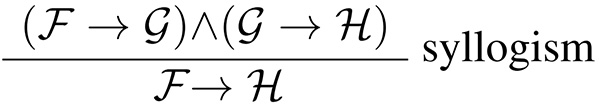
The other example below defines the meaning of conjunction ∧ formally:
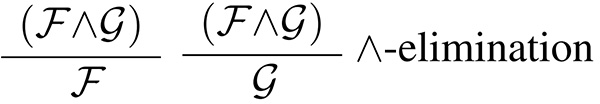
Of course, we can consider invalid steps such as:
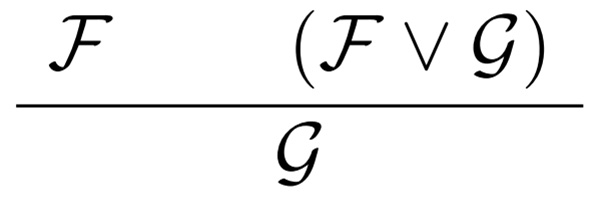
From these examples, we were then able to obtain important points in deductive reasoning. First, deductive reasoning can be defined as a form of thought in which a conclusion is derived from a set of premises following specific rules. Second, since we can consider infinite patterns of formulas as premises and a conclusion, we have infinite patterns of such rules (including both valid and invalid rules).
Next, we considered multistep deductions. Figure 2 shows how a syllogism can be derived by multistep deduction constructed from other “atomic” rules.
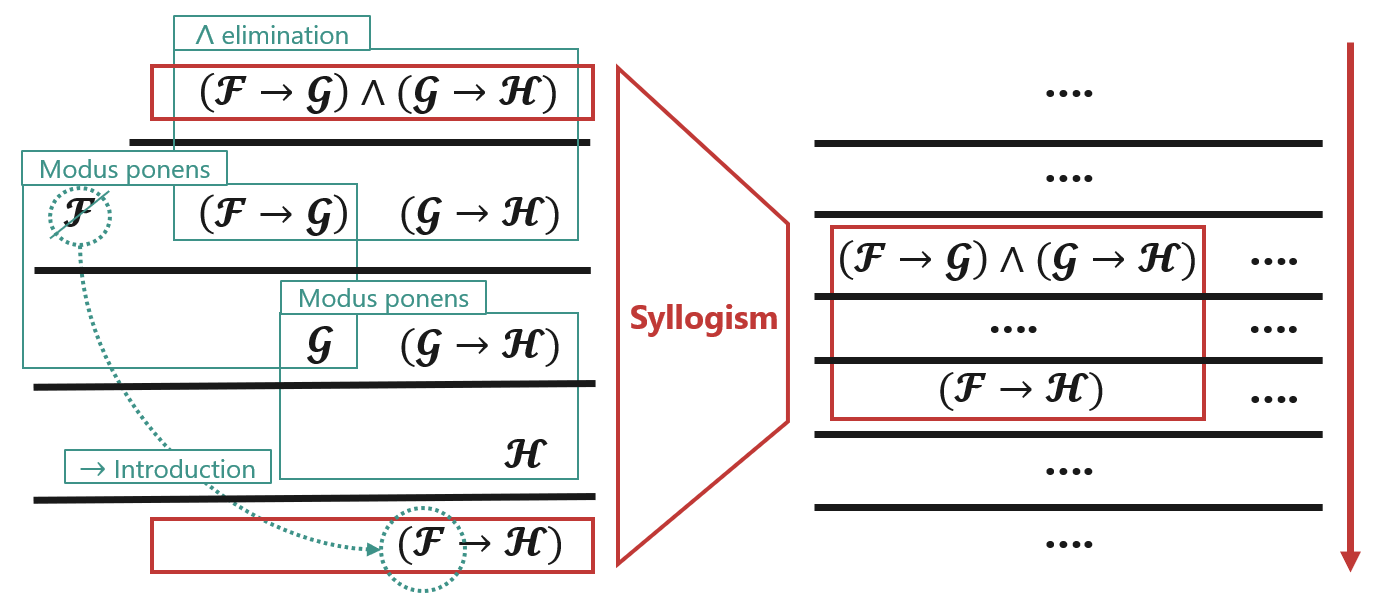
Figure 2. An example of multistep deduction constructed from the axioms, which derives a syllogism
Indeed, in formal logic, there is a set of atomic rules called the axioms, and the following is known:
Theorem: Completeness of first-order predicate logic [10]
Any valid rule is derivable by multistep deduction constructed from the axioms. Further, any rule derivable by multistep deduction constructed from the axioms is valid.
Here, the completeness theorem gave us important insights into our corpus design: that the multistep deduction constructed from the axioms can express diverse patterns of deduction examples.
As discussed in the previous section, the axioms led to diverse patterns of deduction examples.
So, we introduce FLD, which generates deductive reasoning examples constructed from the axioms. (See overview in Figure 3 below).
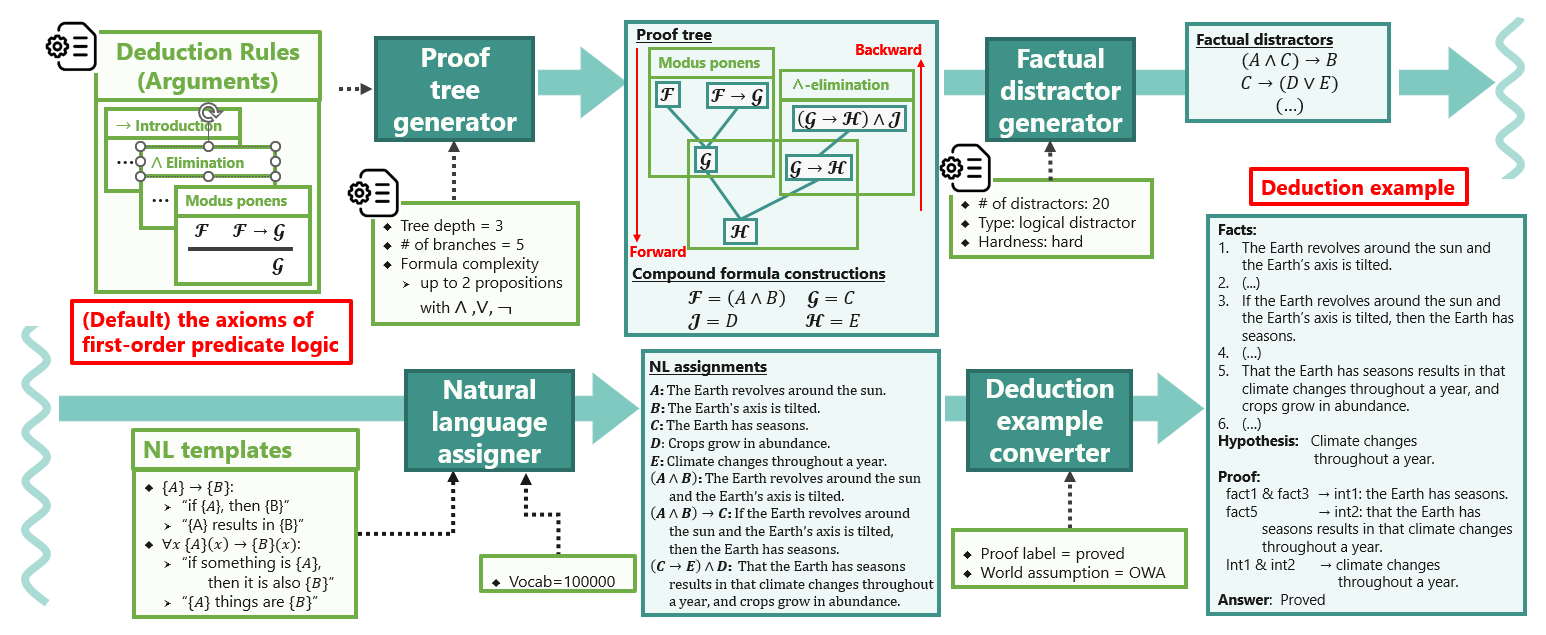
Figure 3. Overview of the proposed FLD framework
FLD first constructs a deduction example using the axioms, in the form of a tree expressed in logical formulas (“Proof Tree Generator’”). After that, it assigns natural language to each formula (“NL assignments”). These assignments are random except logical structures so that referring to existing knowledge cannot help solve the task. Finally, the example is converted into the form of a deduction example (“Deduction Example”). A deduction example is composed of a set of facts, a hypothesis, a proof that (dis-)proves the hypothesis based on the facts, and the answer label. Given a set of facts and a hypothesis, the LLM is required to generate proof steps to (dis-)prove the hypothesis and an answer.
Using FLD corpora, we first investigate how well current LLMs solve the logic. Table 1 shows the performance of different LLMs under a 10-shot setting.
Table 1. LLM performance in a 10-shot in-context learning setting
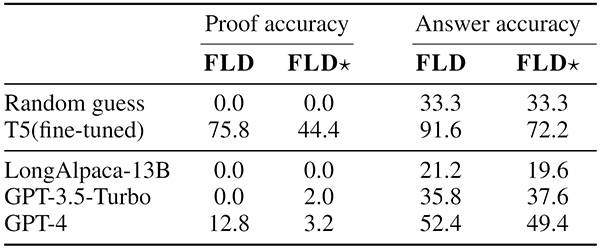
We used two types of metrics: proof accuracy and answer accuracy. We also used two types of corpora: FLD and more challenging version FLD★, which included deduction examples with higher-depth trees. As can be seen, even the most powerful LLM, GPT-4, performed poorly on both corpora in terms of both metrics.
Table 1 also shows that T5, a smaller LM fine-tuned on 30,000 examples while not perfect, performed better than GPT-4. These results suggest that training on FLD could be beneficial.
We then conducted further experiments to compare the effectiveness of FLD with other deduction corpora (Table 2).
Table 2. Few-shot proof accuracies of provers transferred among deduction corpora that uses different sets of deduction rules
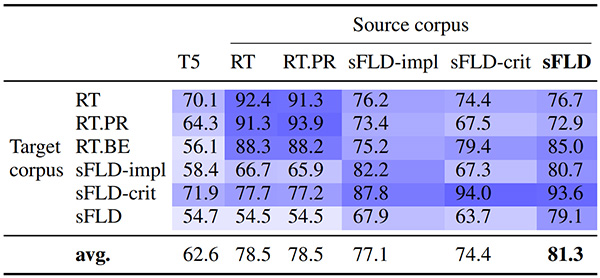
We trained an LM (i.e., T5) on a deduction corpus (”source corpus”) and measured its performance on other corpora (“target corpus”). The LM trained on FLD performed the best on average, i.e., the LM transferred the most robustly to the other corpora. Since the corpora used in Table 2 differs in the set of deduction rules used in proofs, this result suggests that the LM trained FLD generalized the most to other rules. The reason for this strongest generalizability can be attributed to the axioms, which theoretically generalize the best to other deduction rules.
Towards the realization of AI that can reason logically, we proposed a synthetic corpus-based method to teach LLMs logical reasoning and verified its effectiveness through experiments. In the future, we will investigate whether the logical reasoning ability obtained by this approach will generalize to various tasks.
