
YAMAMOTO Dan
Researcher
With the recent progress in the use of "open data," the "unification of terminology" used in the data has become an issue. Currently, different systems use different textual expressions (description formats) even for terms having the same meaning, and adopt different data structures. This situation has made it difficult for open data to be readily utilized.
In order to address this issue, investigations are being made of the "Infrastructure for Multilayer Interoperability (IMI)," which is designed to support utilization of open data by enabling the entire country to share the "vocabulary data" in which textual expressions and data structures are arranged and unified.
(Publication: February 29, 2016)
YAMAMOTOIn order to utilize open data effectively, it is important to arrange that data provided from different areas or different organizations so that it can be used in combination with each other. Presently, however, there is the problem that, different textual expressions of terms (item names) and data structures are used in different fields or by different organizations of the data sources, even for essentially the same type of data, so that the data cannot be used easily. For example, with regard to people's names, sometimes there is a single item under the title of "name" or two items under "family name" and "first name," depending on the data. If things are that way, the data of people's names provided in multiple fields or from multiple organizations cannot be used in combination with each other unless this is worked out. Time is needed to unify the textual expressions (description formats) of the data or to combine two items in a piece of data into one. This is very inconvenient when wanting to utilize open data, isn't it?
YAMAMOTOData from different sources may be more easily utilized if certain words are understood to represent the terms having the same meaning, even though the textual expressions and data structures are different. Moreover, such a problem may not arise if data from different sources use the same textual expressions for terms and employ the same data structures. To achieve this, the scheme called the Infrastructure for Multilayer Interoperability (IMI) can be utilized. In Japan, investigation and development of the IMI scheme are under way led by the Ministry of Economy, Trade and Industry and the Information-technology Promotion Agency (IPA). The project aims to use IMI as the "base for arranging and unifying the 'words' for reading and writing data."
YAMAMOTOWhat is needed is "vocabulary," although it is a bit different from what is generally perceived with the word. In this case, it can be taken as a type of glossary that has arranged and unified the titles, structures and relationships of data items.
Figure 1: An example of structured vocabulary
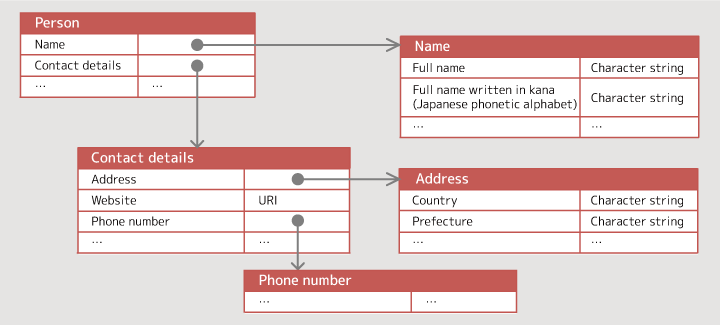
Let me explain by using a "person" as an example. Though it's a simple word, a "person" is composed of a variety of information. It includes information that identifies the person such as "name" and "gender," as well as information associated with the person such as "contact details" and "place of employment." Moreover, such groups of information are further subdivided. "Contact details" comprises such information as "address," "website" and "phone number," while "address" is composed of such information as "country" and "prefecture."
As such, the "vocabulary" is an assortment of words providing the meaning of terms and relationships of terms in a structured manner. Figure 1 shows a simple tree structure to explain only the single term of "person," but in actual vocabularies the structures are far more complicated. For example, "phone number" is a piece of information that is included both in "person" and "organization." As such, factors are connected with each other in a mesh.
Having said this, I admit it is rather hard to understand, isn't it? I myself have been working on the "vocabulary" for over a year, but I still find it difficult to explain.
YAMAMOTOThat is correct. We accumulate the "vocabulary data" that provides the structures of the textual expressions, meanings and relationships of terms, and share it through all society. By doing so, we hope to make open data easier to use. In an effort to develop IMI, Hitachi has worked together with its customers for about a year since the fall of 2013 to investigate what IMI should be like. Let me explain by using a flowchart of how we intend to use the vocabulary data.
Figure 2: Overview of IMI
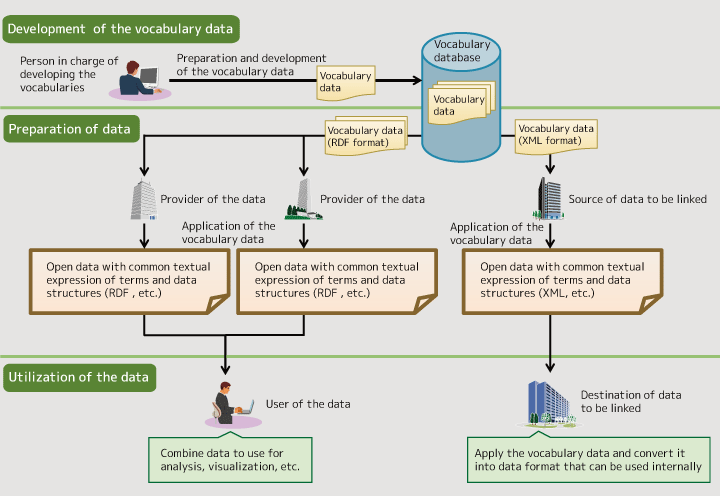
First, we prepare the "vocabulary data" that provides the textual expressions and meaning of terms, etc. in a structured manner, and registered it in the vocabulary database. Here, instead of simply registering it, we work to enhance the vocabulary data by reviewing the relationships with other terms, etc. Next, we use the accumulated sets of vocabulary data to arrange and unify the terms for open data or the data to be linked. As we do so, the vocabulary data is expressed in data formats such as RDF (Resource Description Framework) and XML (Extensible Markup Language) that can be easily handled by machines. By applying these sets of vocabulary data to open data, etc., the textual expressions of terms and data structures can be standardized automatically. Then, the data can be used with unified terms to smoothly conduct analysis and visualization.

YAMAMOTOI agree. At first, intellectuals with knowledge of IMI have to prepare certain parts of it. However, our clients believe that, in order to expand the scope of utilizing IMI, it is ideal that necessary terms are proposed from a variety of fields and are incorporated in the vocabulary data. They say that, rather than one-sidedly asking to "use this vocabulary" they make, they hope that the endeavors will create a base for all society to participate in nurturing the vocabularies.
To meet such a request, we studied the classifications of the vocabulary data to serve as the "framework" of the development, and investigated samples of the vocabulary data as examples of the content. In doing so, we went abroad to conduct surveys because use of vocabulary data was more advanced in some other countries. We met and directly exchanged opinions with knowledgeable persons in the U.S. and Europe. Personally, this was a valuable experience for me. Unless I had been involved in the project, I would never have been able to talk with such prominent people. Through the project, I was able to learn the ideas and thoughts in new fields, which are different from the areas I majored in, and I learned a lot.
YAMAMOTOWe thought that it is difficult to make a sole group of common terms, because IMI should serve as the base of use by a variety of people. That's why we set up a framework in which the vocabularies are divided into three layers. Specifically, they were classified into the "core vocabulary," which is central and is used commonly by everybody, the "domain common vocabulary" that are commonly used by multiple domains, and the "domain-specific vocabulary" that are used only in specific domains. These three layers are expressed in a doughnut-shaped structure, with the "core vocabulary" at the center and expanding into the "domain common vocabulary" and the "domain-specific vocabulary." The "core vocabulary" at the center represents the vocabulary that is commonly understood by everybody. The further away from the center, the fewer people understand the vocabularies.
Figure 3: Classification of vocabularies
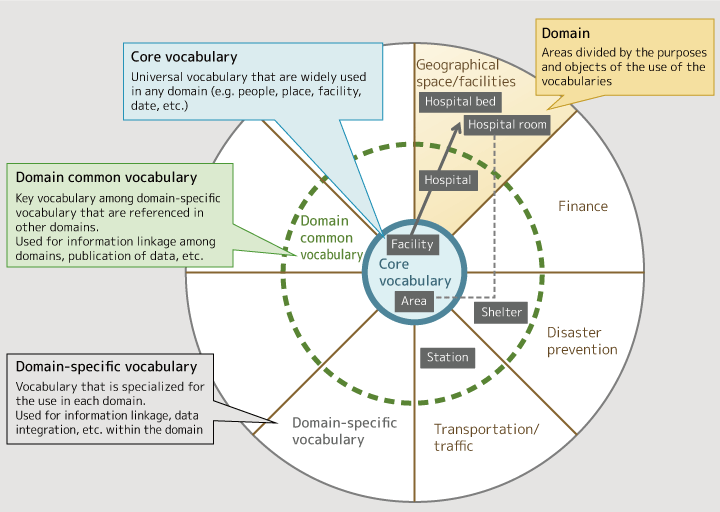
To better understand, let's take the vocabulary related to a "hospital." First, when a hospital is taken as a facility, the word "facility" belongs to the "core vocabulary" as it is used in every domain. On the other hand, the word "hospital" is a word that is referred to in disaster prevention and other domains, although it is not used in every domain. Therefore, it belongs to the "domain common vocabulary." Moreover, such words as "hospital room" and "hospital bed" that are used only by people in a specific domain belong to "domain-specific vocabulary."
Then, what about the area of a hospital room? Although it is one of the factors that constitutes a hospital room, the concept of an "area" is commonly used for a variety of matters. So when expressing the area of a hospital room, the word "area" is used as defined in the core vocabulary, not in the domain-specific vocabulary.
YAMAMOTOWhen we investigated the lineups of the "core vocabulary" and the "domain common vocabulary," we found it very hard to determine "to which degree we should define certain words " and "into which layer such words should be classified" in a balanced manner. We investigated the "core vocabulary" together with our clients, but we had to study the "domain common vocabulary" by ourselves from scratch. Still, we are not experts in all of the domains, and were not able to determine which terms are appropriate. Thus, we invited experts from respective domains to ask for their comments, and added this feedback on what we heard to the vocabulary. That's how we conducted the investigations. We interviewed experts three to four times for each of the domains in which we investigated the vocabulary. As we tried to extract comments and knowledge from the experts, we struggled a lot to determine "which themes we should discuss." It was also difficult to organize their comments, but what was hardest for us was "how to extract comments."
YAMAMOTOI feel that the most important issue is to make the concept of the "vocabulary" and its advantages widely known. For the IMI base to be widely utilized, the concept of the "vocabulary" must be understood by as many people as possible. At present, however, there are still many people even within Hitachi who know nothing of this. Accordingly, we periodically hold study sessions within the company so that the employees will be the starting point for a wider understanding.

YAMAMOTOExactly. Hitachi, Ltd. has also started to consider if new solutions and new products can be created by taking advantage of the know-how that we have obtained from our investigations. For example, suppose there is a situation in which work efficiency suffers because different departments within the organization use different data formats and they find it hard to use mutual data. To address this issue, I think we can provide applications and services which, in coordination with the IMI base, unify the format of the data held by different departments and make it possible to visualize and analyze it. Maybe we can create a new business of integrating the "formats" of data in a similar fashion as the conventional business of data integration.
YAMAMOTOThis project was a very good experience, as I had not had many opportunities to communicate with people outside the company before this. I feel that the opportunity to work with such people through this project helped me to drastically change my mindset. In particular, it was great that I was able to participate in direct discussions with clients. Having participated in such, I renewed my awareness of the importance of "knowledge" and "technologies." Going forward, I will endeavor to further enhance our knowledge and technologies. By doing so, I hope we can become an even better partner of our clients so that we can create great things with them.
