

In order to replace large-scale systems for financial and public services sectors, it is essential to understand what specifications are employed by the current systems in the upstream processes. Understanding the systems that have been used over many years often depends on the experience and knowledge of persons in charge or experts. Accordingly, it has been difficult to conduct surveys of such systems sufficiently, both from a qualitative and quantitative point of view.
The "Information System Scanner" developed by Hitachi analyzes the source codes, data stored in the database and logs, and automatically outputs information required for replacing the systems. The new technology supports understanding the specifications promptly and without omission, enabling a high level of system replacement.
(Publication: September 7, 2016)
OSHIMAIt is a technology to read data that can be obtained directly from a system, and automatically output information relating to the system and relevant business operations. First, the analysis engines of the Information System Scanner analyze the source codes, data stored in the database (DB data) and logs of the subject system respectively. Then, by combining the analysis results, the Scanner outputs specifications required for replacing the system, including the business flow diagrams, screen transition diagrams and logic decision tables. As shown in Figure 1, the Information System Scanner comprises the four elemental technologies of business flow recovery, screen specification recovery, logic specification recovery and database (DB) specification recovery.
Figure 1: Scheme of the Information System Scanner
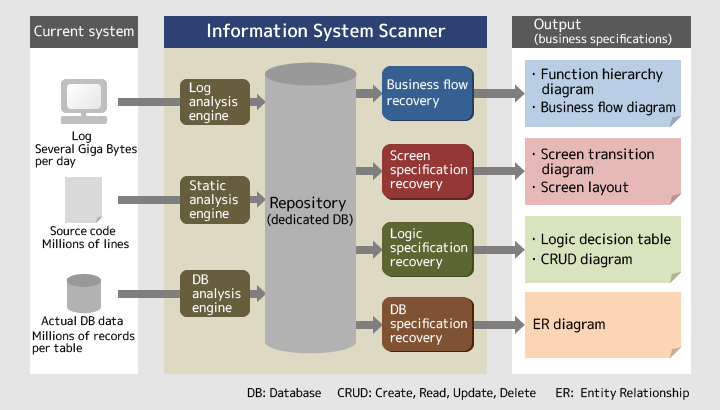
NOJIRITo put it quite simply, the technology clarifies the system specifications and business flows without depending on human memory. You can understand a system or a business scheme to a certain extent if you ask someone who has deep knowledge about it. But human memory sometimes is ambiguous, mixes up facts and is subjective, and so can be inadequate in understanding the actual condition. In contrast, the Information System Scanner uses the information that is already in the system or that can be taken from the system at present as the input information. Specifically, it uses only the source codes, actual DB data and logs. Therefore, the output information is effective as evidence that excludes subjective thinking.
OSHIMAIn the last 15 to 20 years or so, when financial and public service sectors wished to renovate their large-scale systems, they have often done so by replacing the current systems and partially adding new functions, rather than building them from scratch. Customers request us to install the new functions in the same way as their current systems. However, if such systems were built 10 or 15 years ago, it takes quite a lot of work and time to discover their functions and installation methods. If we have to spend too much time understanding the current systems, it causes the problem of not fully being able to examine the new functions of the next systems. Suppose we design and install the new functions without fully studying them, and if it is found out in the downstream test processes that the functions are insufficient, we will face a major setback.
NOJIRIMore recently, many customers believe that they have to accelerate the cycle of renewing functions to accommodate new businesses. We at Hitachi were also required to meet such needs through technological offerings.
Figure 2: Purposes of the Information System Scanner
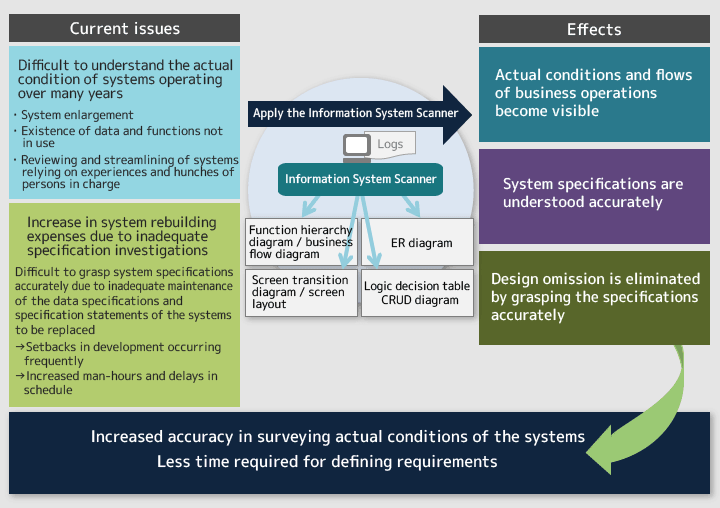
NOJIRIThe Scanner outputs information in a format that is understandable to some extent even for people who know much about the business, if not they are system developers. If customers are given a million lines of logs as is, they wouldn't understand what the offering represents even though it is a real thing. That's why we have elaborated it so that the Information System Scanner outputs information that is genuine and in a format that is easy to understand.
OSHIMAWhen applied, this technology clarifies not only the system specifications and business flows but also the actual use status of the relevant system. This is helpful for preventing the system from becoming too big because, when we discuss the specifications of the next system with the customer, we can point out that certain functions have rarely been used by providing proof.
OSHIMAWe had been engaged in the research of the respective elemental technologies separately since before. However, it was just three years ago that we started using trial and error methods to find out whether we can combine such technologies to enable outputs of business specifications. The project was initiated on such a large scale that we had some worries, but we also expected that combining the technologies should enhance the accuracy of the outputs and produce something new.
NOJIRII had been involved in the project at its proposal stage but shortly left it to work on another research topic. I returned to the project in its second year, wondering how it came along during my absence, and was surprised to find that great results were generated in a year. So I took part in the research, asking myself what I could do to help the project make progress at that pace.
OSHIMASince the second year of the project when Mr. Nojiri joined, we have worked by dividing our coverage into the four elemental technologies of business flow recovery, screen specification recovery, logic specification recovery and DB specification recovery. I was in charge of DB specification recovery and Mr. Nojiri covered logic specification recovery.

OSHIMAWe have developed the DB specification recovery technology to show the tendencies of the data stored in the database. Where a system has been used for a long time, we would come across something like a new specification that did not exist initially when the system was developed. Let's use employee codes as an example. Normally, an 8-digit number would be entered for an employee code. However, once you enter 8 Zs (ZZZZZZZZ), the code would become commonly available and applicable to any employee. That could happen. You cannot find such a specification even if you investigate the design documents prepared when the system was developed. Therefore, we worked so that the technology makes statistical analysis of the actual DB data and automatically extracts the formats and singular values of the DB columns. With this technology, it is possible to automatically detect the presence of singular values. In the case of the employee code, for example, it detects "ZZZZZZZZ" as a singular value, although the format is set to be an 8-digit number.
NOJIRIIn developing the logic specification recovery technology, we set as the final goal the extraction of "business operation rules" from the source codes. The "business operation rules" mean conditions or requirements. For example, if the entered amount is one million yen or more, a warning message must be sent. Meanwhile, "logic" connects elements, such as between business operations and screens or the database. We also aimed to specifically clarify which elements are connected by logic. In doing so, the keyword was "program slicing."
NOJIRIMostly, the source codes are divided into many components. A component processes the information inputted by the user and passes it to the next component, which further processes the information and passes it to another. In this way, information is processed and relayed one-by-one. In order to pursue this relay of processing, we introduced the thinking of "program slicing." It means cutting out programs relating to certain data from the components they are installed in. It's just slicing the programs, indeed. You take out only certain portions of the data processed by particular programs and cut only some portions of programs, and then combine the extracted portions from head to tail.
Suppose the head is the portion of data that is entered on the screen, and the tail is the portion that is stored in the database. Run the program slicing, and you get all the conditions that have not been removed. You only need to look at these portions to extract the logic, without looking at other portions that are not necessary. You also clearly get the screens and data to be used for the relevant operations. Thus, you can securely pursue the correlation of elements connected by the logic. That's what we have achieved with the technology.
OSHIMAIn the laboratory, we can conduct research on the assumption that all the input information is available. But it is not necessarily like that in the actual workplace. Depending on how the systems are configured, certain types of information cannot be gained. However, if no analysis is possible unless all information is available, the frontline people won't use the technology. We need to get fairly good results even if the input information is not perfect. To do so, we divided the input information into classes according to the type and volume. With this arrangement, the analysis accuracy varies depending on the availability of the input information. If a certain portion is missing, the analysis should include guesses and so is less accurate and doubtful. Within the conditional restrictions, we had to consider what we could output at each level of accuracy to understand the business operations. That was a tough part of our work.
NOJIRIIn the second year of the project, we set up a User Community. Its members are people in the business divisions and affiliated companies who are likely to use this technology in the field. The Community meets about once a month or so, and we report the progress status to the members and collect information on their needs in terms of business operations. Such a cross-division event held once a month may not be so often. We started this Community with the aim of growing the technology into a business. The project had generated a lot of results in the year since it started, and it would have been a waste if the achievements are left unused. That's what we thought. The Community has continuously held to date.
OSHIMAAt occasions for introducing the latest technologies of Hitachi, many customers gave us favorable comments. Some said they want to somehow enhance the systems that have been left untouched for many years, while others wished they could have used this technology when they renewed the systems three years ago.
Internally, we fed back the analysis results of the sample systems used for evaluation to the departments that developed them. People were positive about the results, saying that they were happy to learn that actual conditions were extracted, which they could not find through design documents or within their knowledge. From the business point of view, the technology seems likely to offer cost benefits, as it prevents setbacks due to omissions in investigations.

NOJIRII think a major target is to connect the Information System Scanner with design tools. Presently, the Scanner can output specification documents at the end of its automatic operations. The outputted specification documents must be checked by humans. To allow the use of output information from the Scanner as input information for design tools, another round of input information must be added.
In addition, I want to further reduce a lot of the noise that still exists in the output information. For example, I believe that if we can incorporate the knowledge of machine learning into the Scanner and let it cut needless data by fully utilizing computer capacity, we should be able to reduce the noise and eliminate omission of important information.
OSHIMASince I joined the Company, I've been engaged in research and development, always wanting to create better system architectures. I hope to create a new architecture that skillfully combines and coordinates the portions taken from the current systems that have long been used, with the portions to be newly developed by utilizing Fintech and "blockchain" which are hot topics in the financial sector.
NOJIRITo date, I have conducted research, mainly focused on how to create software easily and quickly. More recently, however, I feel like expanding my research into a somewhat wider area like the "productivity of white-collar workers." Hopefully, what are called "chores" in their work could be done by machines. Artificial intelligence is also a promising field.
On the other hand, I think that we won't fully believe in machines in the future. At present, many people including myself expect that what machines do is entirely correct, and believe that "machines should always be accurate," whether or not they actually are. But it's not going to be like that. I think we should assume that machines can make mistakes, just as humans do. Based on this assumption, we should evaluate what machines do to skillfully utilize them. This is necessary to take productivity to the next stage. This may be a long shot, but this theme interests me.
