Demonstrating 250 times faster performance by using GPUs to implement a new algorithm
October 18, 2019
Table 1 A line-up of CMOS annealing that can address a variety of optimization problems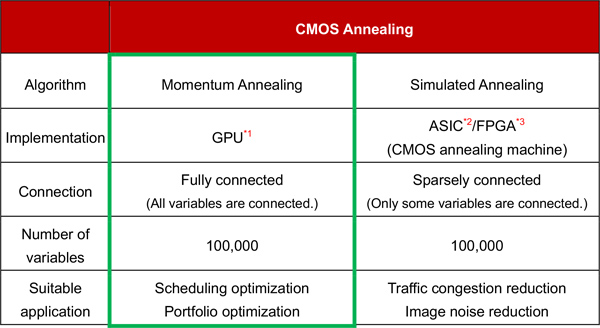
Hitachi, Ltd. has developed an optimization algorithm for fully connected models to find practical solutions quickly for large-scale optimization problems, such as scheduling optimization and portfolio optimization problems. The algorithm was implemented on GPUs and tested using fully connected combinatorial optimization problems with 100,000 variables*4. We confirmed that the approximate solution could be obtained 250 times faster than the conventional algorithm running on a modern CPU*5. Using this algorithm and CMOS annealing machine developed by Hitachi, a wide range of real problems faced by customers can now be addressed (Table 1). Going forward, Kyōsō-no-Mori*6 opened by Hitachi will be used as a research and development base to accelerate the creation of innovation through open collaboration. Through Kyōsō-no-Mori, Hitachi will work with internal and external partners to promote the production of solutions that contribute to solving increasingly complex social problems.
The algorithm proposed by Hitachi is called Momentum Annealing (MA), which solves a combinatorial optimization problem called QUBO*7. MA converts a QUBO (Figure 1a), in which all variables are connected to one another, into another QUBO (Figure 1b) where the variables connect in the form of a complete bipartite graph, while maintaining an optimum solution. The optimization algorithm based on the Markov chain Monte Carlo method represented by Simulated Annealing (SA) guarantees to reach the optimal solution or its approximate solution by updating variables sequentially and stochastically. Although variables that are not connected to any others can be independently and simultaneously updated, simultaneous updates cannot be made under any other conditions. Therefore, when we solve a fully connected QUBO, we can update only one variable at a time. However, if the connection between variables is in the form of a complete bipartite graph, the variables on the left in Figure 1b are not connected and can be updated at the same time. The same is true for the variables on the right. Therefore, we can execute parallel computation and reduce the time.
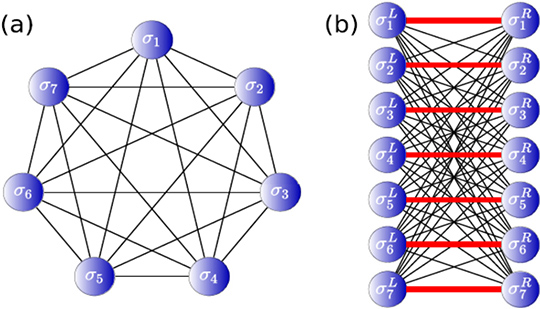
Fig. 1 Conversion of Ising model into bipartite graph.
MA searches the solution using the model with the new connection shown by the red line in Figure 1b. If the effect of these connections is too significant, it is more likely to be trapped in the local solution, making it difficult to find a good solution by exploring various states. On the other hand, if the coupling is too small, the optimal solution of QUBO (Figure 1a) to be solved and that of QUBO (Figure 1b) dealt with in MA will be different and not appropriate. It is necessary to make the new connection as small as possible while the optimum solution of each problem agrees. To achieve this goal, we derived an inequality using the maximum eigenvalue of the matrix representing the connection between the variables and set the strength of the connection of the red line appropriately.
To conduct quick solution searching for QUBO with all variables connecting to one another, we generated an MA program that makes use of GPUs that are widely used for scientific computing such as deep learning. To solve QUBOs with 100,000 variables, we ran MA on 4 NVIDIA Tesla P100*8 and reported that it took 1/250 of the computational time to reach an accurate solution equivalent to an approximate solution obtained with the Sahni-Gonzales (SG) optimization algorithm compared with the SA run on IBM Power 8*9 (Figure 2).
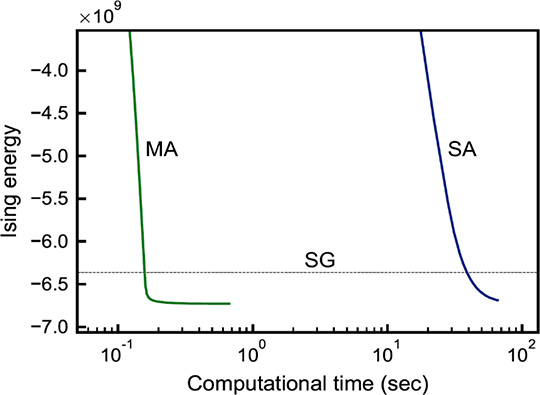
Fig. 2 Experimental results obtained with MA and SA solving a fully connected Ising model with 100,000 spins. The horizontal axis represents the computation time and the vertical axis represents the objective function value of the combinatorial optimization problem.
For more information, use the enquiry form below to contact the Research & Development Group, Hitachi, Ltd. Please make sure to include the title of the article.





