What is currently required in the area of data analytics is to increase the speed of analysis processing. In recent years, however, there is a growing number of cases in which the processing load has become too high for CPUs (central processing units) to handle, posing a new obstacle to increasing the analysis speed.
To address this issue, members of a storage team and a database team at Hitachi have worked together to develop new data processing technology to reduce loads on CPUs. Further efforts are being made to improve the technology through customer co-creation.

WATANABE Satoru
Senior Researcher

FUJIMOTO Kazuhisa
Cheif Researcher
(Publication: March 8, 2017)
WATANABEYou are right. Conventionally, it was generally perceived that data analytics is conducted by experts. The situation is changing largely. What is now needed is "self-service BI," which allows anyone, not just experts, to readily conduct data analysis. For example, when sales staff of insurance companies talk with their customers, they would use BI tools on the spot to analyze the customers' information in real time and propose the most suitable insurance products. Such a way of using BI tools is sought. This means that data analysis is applied in increasingly wider areas. As things go that way, many users will access data at high frequencies. This should raise the users' needs to enhance the performance of the calculation processes of the systems.
FUJIMOTOOn top of that, there is a trend of increasing focus on "big data." So expectations for more enhanced processing capabilities, especially for faster data processing speed, will continue to grow. Previously, processing bottlenecks were found in storage devices and databases, and a variety of measures were taken to solve the problems there. For example, flash memories were incorporated into storage devices to increase their processing speed by nearly 100 times, and column-store databases were introduced that achieve significantly higher performances. As such, we saw improvements in the performances of storage devices and databases. Now that they perform at a higher speed, however, a new problematic situation has occurred in which CPUs, which conduct arithmetic processes of data, cannot catch up with their speed.
Figure 1: Changes in processing bottlenecks in data analytics
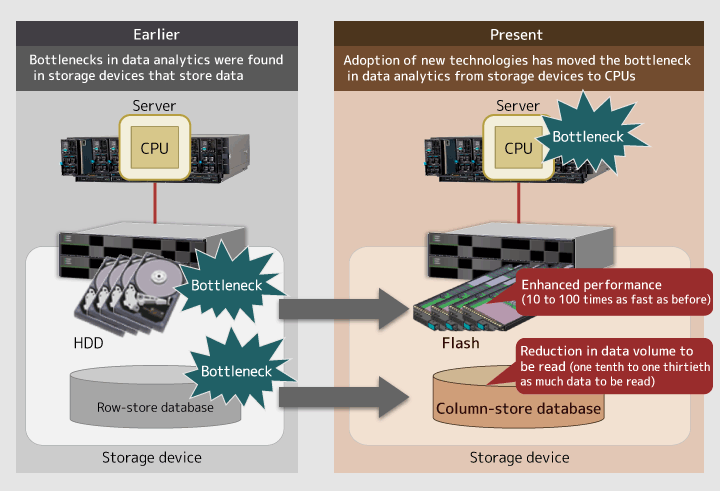
WATANABEYes, we are. When you hear people talk about "big data processing," you may think about the "in-memory database" as a keyword. However, wherever the data is stored, the performance remains the same because processing is conducted by CPUs anyway. Thus, we had to create a new mechanism that could offload CPU computation.
FUJIMOTOIn our development, we decided to develop a hardware-based accelerator that increases the processing speed of the CPUs by offloading CPU arithmetic processing. An accelerator is a type of hardware or software used to enhance specific functions and processing capabilities. Because both of us were originally engaged in the research of reducing the CPU load on the storage and database sides, we determined to make a tag team in conducting the research and development.
WATANABEIn the data analytics conducted to date, CPUs had to process all data including the data not used for analysis. As the data volume becomes huge and the data is accessed more often, it is only natural that CPUs have more loads and cannot fully conduct processing. So, we focused on how to reduce the data volume CPUs have to process, and started our activities by discussing the direction of the research and development by sharing mutual research results.

FUJIMOTOBecause our specialty fields were different in the first place, often there were gaps in our discussions for the first year. However, after we fully gave our comments and held thorough discussions, we were able to conduct development in good coordination with each other.
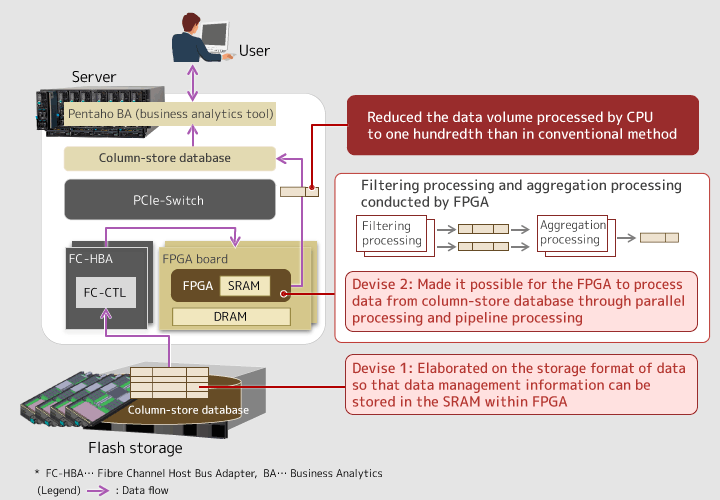
In the research, we studied methods to conduct minimum data processing in advance so that the data volume handed to CPUs is reduced. Specifically, "filtering processing" and "aggregation processing," which are often used in data analytics, are first conducted by field-programmable gate arrays (FPGAs), and the processing results are then transferred to CPUs. This reduces the load of processing conducted by CPUs. In doing so, a technology to directly transmit data from storage devices to FPGA boards is needed. Our storage team was in charge of the development for this part. We had to consider how directions should be given to FPGAs based on the users' demand for analysis, and how data should be transferred back and forth between storage devices and FPGAs as well as between FPGAs and CPUs. Such technology did not exist before, and we often had to struggle.
WATANABEOur database team developed the technology to align column-store databases with FPGAs. We had precedents for combining conventional row-store databases and FPGAs but not for column-store databases. There were big differences in everything, such as how the data is lined, held and processed, between row-store databases and column-store databases, and we had a hard time developing the technology. On top of this, we elaborated on how to store and process data in the databases to realize the required processing speed.

WATANABEThe first was the data format, or how the data is stored. Column-store databases have "data management information," aside from the data itself, in order to manage how the data is compressed and where the data is stored. The data management information is like a dictionary that shows where the data is allocated, and must be referred to whenever the data is accessed. To reduce the CPU loads and increase the processing speed, you need to bring the data management information to FPGAs for processing. However, if the data is stored in an ordinary manner, the data management information is bigger in size than the memory capacity of FPGAs. That's why we worked to divide the data into smaller pieces and store them so that the size of the "dictionary" is within the memory capacity of FPGAs.
The second was increasing the speed of database processing conducted by FPGAs. To increase the processing speed of FPGAs, you can apply either parallel processing or pipeline processing. However, for column-store databases, it is rather difficult to employ these methods because of the issue of the order in which the data is lined. Therefore, we worked so that filtering processing can be done in the column format and, for aggregation processing, we reconstructed the column format into the row format for processing. By doing so, we achieved a faster processing speed.
FUJIMOTOIn fact, the technology to offload database processing to hardware devices has existed for nearly 30 years. But it has gathered little attention, because technological improvements in CPUs were achieved at a faster pace. In our development, we re-used the technology and applied it to the column-store databases. We also endeavored to figure out where to conduct parallel processing and pipeline processing. All these efforts have achieved a data analytics speed that is 100 times that using conventional methods. This achievement justified the hard times we had to go through, as we experienced a lot of trouble in development, both for storage devices and databases.
Figure 2: Overview of the data processing technology utilizing FPGAs
FUJIMOTOExactly. We publicly announced the research results at early stages and created products while listening to the customers' comments. That's the style employed in our research and development. By making announcements before commercialization, we can learn in advance what the customers' needs are, and reflect them in the products. This method has already been used in software development. However, probably it is rather rare that such a method was employed in developing products including hardware, like our research.

WATANABEIn conducting research, it is important that customers are interested in the research. Once they get interested, it triggers conversations with the customers and we may receive a variety of ideas from them. If we conduct research alone, we inevitably tend to be self-satisfied. So I feel that the research activities we have conducted are very useful.
For the research, we received many inquiries from inside and outside Japan at such occasions as technical exhibitions in North America and issuance of a press release. Many of the responses were from customers in finance, telecommunication, e-commerce and other industries who handle big data, as we initially anticipated. Moreover, some customers gave us actual data, and we are currently conducting a demonstration experiment using the data to verify the effectiveness of this technology.
FUJIMOTOWe have received requests from customers to further increase the processing speed and offload other processing tasks from CPUs. It is not easy to do so, as there is a limitation in the logic blocks we can put in FPGAs. But we hope to enhance the products to meet the customers' requests as much as possible. For that purpose, we may use the latest devices as well.

FUJIMOTOThrough our experiences in developing the technology, I keenly felt that it will become even more important in the future to make technologies open to the public at early stages and create products together with customers. I also believe strongly that we require changes as well. In particular, we must bear in mind that we need to accelerate the pace of development more than before. This is because the key to success is how quickly we can demonstrate the actual item after we receive requests. This is worth doing and, for that matter, we must change ourselves and keep taking on challenges.
WATANABEThe accelerator we have developed, which is to increase the processing speed of CPUs, is one of the technology subjects currently on stream. Going forward, technological development is expected to keep proceeding, such as new memory devices and storage devices created and new data processing methods developed. I hope we can tactfully utilize such trends of society and offer products that meet the needs at each point in time.
To add this, when we communicate with the customers, I feel that they show more interest in certain technology if we demonstrate that the technology is new and unprecedented. In our latest development, the keyword of "accelerator" gave the customers the impression that it is a new technology. Through our activities, we were able to build a good relationship with the customers. I hope we can keep this good trend going into the next round of our development.



