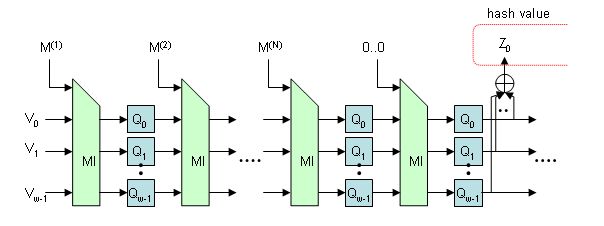
Luffa is a new family of hash functions submitted to NIST for their cryptographic hash algorithm competition.
Luffa is a variant of a sponge function proposed by Bertoni et al., whose security is based only on the randomness of the underlying permutation. Different from the original sponge, Luffa uses plural permutations in parallel and a stronger messsage injection function as depicted in the above figure.
The latest version of the Round 2 package and some of the parted contents can be downloaded.
And the Round 1 information is archived here. The obsolete documents can be found here.
The list of the newer coming security reports on security analysis, software and hardware implementations will be provided here.
| Luffa-256 | |||
|---|---|---|---|
| Reference | Platform | Throughput (cycles/byte) | Notes |
| Supporting document | Intel Core2 Duo E6600 2400 MHz (64-bit mode) | 26.2 | ANSI C |
| 16.3 | C+SSE intrinsics | ||
| 13.3 | Assembly | ||
| Intel Core2 Duo E6600 2400 MHz (32-bit mode) | 31.2 | ANSI C | |
| 19.8 | C+SSE intrinsics | ||
| 13.8 | Assembly | ||
| ARM ARM926EJ-S (4KB cache) | 91.1 | ANSI C | |
| AVR ATmega9515 (8KB flash memory + 512B RAM) | 732.1 | 808B ROM + 134B RAM | |
| Renesas H8/38024F (32KB flash memory + 1KB RAM) | 1624.8 | 976B ROM + 144B RAM | |
| Oikawa et al. | ATI Radeon HD5750 | 9272.3 Mbps | C + OpenCL, with memory transfer, processing 4096 independent messages |
| 21906.0 Mbps | C + OpenCL, without memory transfer, processing 4096 independent messages | ||
| NVIDIA GeForce GTX260 | 25335.0 Mbps | C + OpenCL, with memory transfer, processing 6912 independent messages | |
| 15053.3 Mbps | C + OpenCL, without memory transfer, processing 6912 independent messages | ||
| Luffa-384 | |||
| Reference | Platform | Throughput (cycles/byte) | Notes |
| Supporting document | Intel Core2 Duo E6600 2400 MHz (64-bit mode) | 40.2 | ANSI C |
| 18.5 | C+SSE intrinsics | ||
| 15.0 | Assembly | ||
| Intel Core2 Duo E6600 2400 MHz (32-bit mode) | 46.7 | ANSI C | |
| 22.3 | C+SSE intrinsics | ||
| 15.5 | Assembly | ||
| ARM ARM926EJ-S (4KB cache) | 129.5 | ANSI C | |
| AVR ATmega9515 (8KB flash memory + 512B RAM) | 1055.4 | 934B ROM + 166B RAM | |
| Renesas H8/38024F (32KB flash memory + 1KB RAM) | 2296.8 | 1136B ROM + 176B RAM | |
| Luffa-512 | |||
| Reference | Platform | Throughput (cycles/byte) | Notes |
| Supporting document | Intel Core2 Duo E6600 2400 MHz (64-bit mode) | 55.6 | ANSI C |
| 31.7 | C+SSE intrinsics | ||
| 23.8 | Assembly | ||
| Intel Core2 Duo E6600 2400 MHz (32-bit mode) | 64.9 | ANSI C | |
| 36.0 | C+SSE intrinsics | ||
| 26.8 | Assembly | ||
| ARM ARM926EJ-S (4KB cache) | 169.7 | ANSI C | |
| AVR ATmega9515 (8KB flash memory + 512B RAM) | 1427.0 | 1040B ROM + 198B RAM | |
| Renesas H8/38024F (32KB flash memory + 1KB RAM) | 3028.8 | 1312B ROM + 208B RAM | |
| Luffa-256 | |||||
|---|---|---|---|---|---|
| Reference | Technology | Size | Throughput | Clock frequency | Notes |
| Supporting document | ASIC, UMC 0.13 µm | 30.8 KGE | 31960.0 Mbps | 1124 MHz | Fully autonomous, Throughput optimized |
| 19.6 KGE | 98.7 Mbps | 344 MHz | Fully autonomous, Area optimized | ||
| Namin and Hasan | ASIC, STM 90 nm | 122 KGE | 25702 Mbps (9.96 ns per 256-bit data processing) | 100 MHz (9.96 ns delay) | Imple. of Luffa v1, Core functionality (A full round processing + output function + I/O registers) |
| FPGA, Altera Stratix III | 16552 ALUT | 12042 Mbps | 47 MHz | ||
| Knežević and Verbauwhede | ASIC, UMC 0.13 µm | 18.3 KGE | 2461.5 Mbps | 250 MHz | Fully autonomous, Area optimized |
| Tillich et al. | ASIC, UMC 0.18 µm | 45.0 KGE | 13741 Mbps | 483 MHz | Fully autonomous, Throughput optimized |
| Kobayashi et al. | FPGA, Xilinx Virtex-5 | 1048 slices | 6343 Mbps | 223 MHz | Fully autonomous, Throughput optimized |
| 1002 Mbps | Fully autonomous, including communication overheads by proposed interface | ||||
| Mikami et al. | ASIC, TSMC | 10.3 KGE | 538 Mbps | 806 MHz | Fully autonomous, Area optimized |
| FPGA, Xilinx Virtex-5 | 548 slices | 1660 Mbps | 162 MHz | ||
| 355 slices | 33.3 Mbps | 50 MHz | |||
| Luffa-384 | |||||
| Reference | Technology | Size | Throughput | Clock frequency | Notes |
| Supporting document | ASIC, UMC 0.13 µm | 50.1 KGE | 23126.0 Mbps | 813 MHz | Fully autonomous, Throughput optimized |
| 29.5 KGE | 73.8 Mbps | 344 MHz | Fully autonomous, Area optimized | ||
| Knežević and Verbauwhede | ASIC, UMC 0.13 µm | 27.1 KGE | 1882.4 Mbps | 250 MHz | Fully autonomous, Area optimized |
| Luffa-512 | |||||
| Reference | Technology | Size | Throughput | Clock frequency | Notes |
| Supporting document | ASIC, UMC 0.13 µm | 65.1 KGE | 19617.0 Mbps | 690 MHz | Fully autonomous, Throughput optimized |
| 39.8 KGE | 35.2 Mbps | 344 MHz | Area optimized | ||
| Knežević and Verbauwhede | ASIC, UMC 0.13 µm | 37.3 KGE | 1523.8 Mbps | 250 MHz | Fully autonomous, Area optimized |
