17 June 2020

Yosuke Kaga
Research & Development Group, Hitachi, Ltd.
Searching an enormous collection of images such as those for available for vein patterns or faces requires a lot of calculation time and memory consumption. If we can establish fast and light-weight image retrieval, it will be possible to verify the authorized persons in scenes such as hands-free payment, access control or to identify a suspicious person in immigration control and public spaces. In this blog, we introduce our Probabilistic Deep Hashing (PDH) for extremely fast image matching. In the PDH, images are converted into hash codes represented by compact binary vectors using deep learning. The hash code can be matched more than 100 million times per second, and large-scale image retrieval can be performed rapidly.
CBIR (Content-Based Image Retrieval) is an approach to search for similar images by entering images as queried instead of keywords. The scope of this CBIR is broad. When this technology is used for biometric information such as vein patterns and faces, it will be possible to identify a person from a large number of registered users. This technology makes it possible to create an authentication platform that does not require PINs or cards at all. By using this authentication platform, highly convenient payment services can be realized. Moreover, this platform can be applied to access control, immigration control and suspicious person detection, and more (Figure 1).
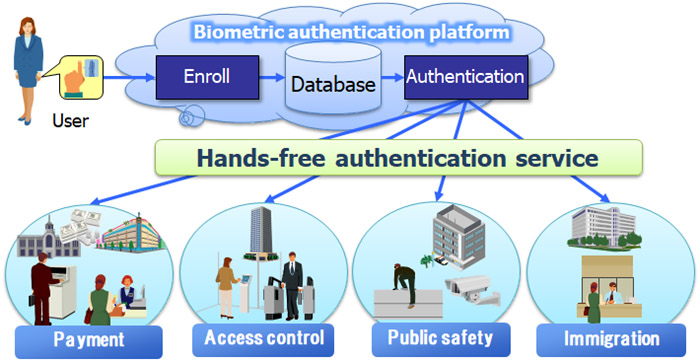
Figure 1: Applications of biometric authentication
However, in order to simply search for similar images on N images, the distance between the query image and the image to be searched needs to be calculated N times. In addition, it is necessary to hold N images when searching. These features mean that the retrieval time and memory consumption will be huge when a large number of images are to be retrieved.
Probabilistic Deep Hashing (PDH) is our newly proposed hashing method for efficient image retrieval and shown in Figure 2.
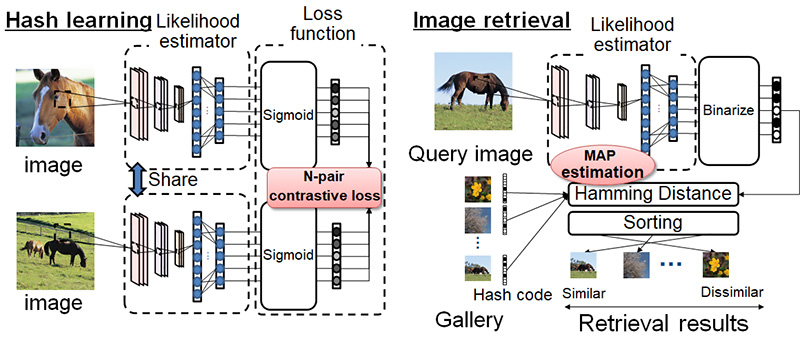
Figure 2: Architecture of our PDH
The PDH uses deep learning to learn the hash function and convert the images into hash codes. We devised a loss function for the Hamming distance between the hash codes of two images. We compute the expected value of the hamming distance from the posterior probabilities of each dimension of the hash codes, and the loss function consists of the error between this expected value and the ideal hamming distance. Furthermore, the hamming distance between hash codes is calculated during image retrieval, and we show that the calculation of this hamming distance is equivalent to maximum a posteriori estimation. In this way, we proved that the PDH can be used for a probabilistically optimal search.
To show the effectiveness of our PDH, we evaluate the performance of hashing methods by using image datasets. Figure 3 shows the accuracy of image retrieval using PDH compared to other methods. Mean Average Precision (mAP) is used as a measure of accuracy. From the figure, it can be confirmed that the PDH can retrieve images with higher accuracy than the conventional hashing methods.
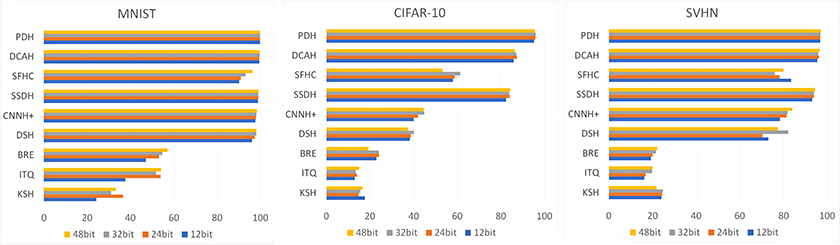
Figure 3: Mean average precision of hashing methods
Moreover, we evaluate the retrieval speed and the size of hash codes. As shown in Table 1 and Figure 4, hashing realizes extremely fast and light-weight image retrieval.
Table 1. Matching speed of hashing
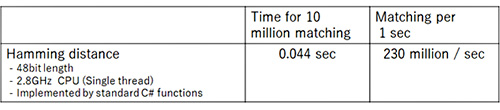
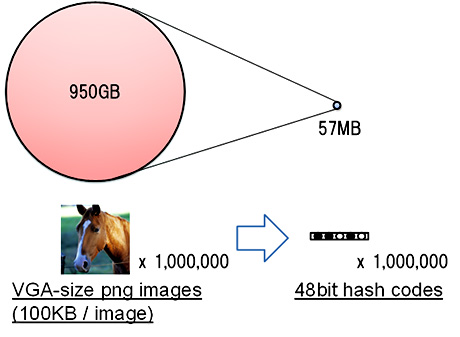
Figure 4: Storage consumption of hashing
PDH can convert images into a compact hash code and perform fast and memory-saving searching for large-scale images. Furthermore, by applying PDH to biometric information such as vein patterns and faces, a hands-free authentication platform that identifies individuals from a large-scale biometric database can be established. For more detailed information, we recommend referring to our paper [1].
Thanks to my co-authors Professor Masakatsu Nishigaki and Associate Professor Tetsushi Ohki from Shizuoka University, and Masakazu Fujio and Kenta Takahashi from Hitachi, Ltd., with whom this research work was jointly executed.






